<p>(Replace this first paragraph with a brief description of your new category. This guidance will appear in the category selection area, so try to keep it below 200 characters.)</p>
<p>Use the following paragraphs for a longer description, or to establish category guidelines or rules:</p>
<ul>
<li>
<p>Why should people use this category? What is it for?</p>
</li>
<li>
<p>How exactly is this different than the other categories we already have?</p>
</li>
<li>
<p>What should topics in this category generally contain?</p>
</li>
<li>
<p>Do we need this category? Can we merge with another category, or subcategory?</p>
</li>
</ul>
<p><small>1 post - 1 participant</small></p>
<p><a href="https://sq.giai.org/t/about-the-siai-admission-category/27">Read full topic</a></p>
MSc in Artificial Intelligence
<p>Hello,</p>
<p>I am interested in the one-year course so could you provide me with some more information we also we could make a phone call,please let me know.</p>
<p>BR,</p>
<p>Elvi</p>
<p><small>2 posts - 2 participants</small></p>
<p><a href="https://sq.giai.org/t/msc-in-artificial-intelligence/119">Read full topic</a></p>
Master of AI - admission
<p>Dear Sir/Madam,</p>
<p>I am currently a graduating Master’s student at (Hidden), pursuing a Master of Science in Energy, and I am interested in applying for the Master in Artificial Intelligence at your university for the next academic year.</p>
<p>Could you please inform me if it is still possible to apply for this program? Additionally, I would like to know if I need to complete any preparatory program before starting the Master’s in AI. I am also interested in finding out if I qualify for a reduced tuition fee.</p>
<p>I look forward to your response.</p>
<p>Kind regards,</p>
<p>Thomas Ponnet</p>
<p><small>3 posts - 3 participants</small></p>
<p><a href="https://sq.giai.org/t/master-of-ai-admission/117">Read full topic</a></p>
GIAI Books (Korea)
GIAI Books (Korea)는 GIAI 연구자들이 작성한 콘텐츠 중 일부를 묶어 e-Book으로 발행한 자료들입니다. AI 및 데이터 과학, IT 산업, 스위스 AI대학(SIAI) 교육 자료, 대형 언어 모델, 금융 투자 등, 데이터 과학이 적용되는 분야 전반에 걸친 주제들을 담고 있습니다
[공지] 2025학년도 SIAI 지원 희망자들 대상 온/오프라인 설명회
[공지] 2025학년도 SIAI 지원 희망자들 대상 온/오프라인 설명회
Picture

Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Published
지난 1년 사이 여러차례 공지가 나간대로, 이제 2025년 가을 학기부터 SIAI 모든 운영이 본사인 GIAI로 넘어갑니다.
공식적으로 SIAI 법인 소유권이 넘어가는 3월 말 전에 마지막으로 설명회를 하면서 그간 남았던 굿즈(Goods)들을 드릴까 하는데, 이왕이면 SIAI 입학을 희망하는 학생들에게 주는 편이 맞지 않을까 싶어 아래의 일정으로 온/오프라인 설명회를 진행하겠습니다.
SIAI 입학 희망학생 대상 온/오프라인 설명회
- 일시: 2025년 2월 22일 토요일 (시간/장소는 참석자에게만 E-Mail로 개별 통보)
- 내용: SIAI 한국인 학생들 성과 소개 및 교육 내용 소개
딱히 금전적인 이득을 바라고 진행하는 행사가 아닌만큼, 아래의 요건을 맞춘 분께는 일괄 초대장을 보내드릴 계획입니다.
- GIAI Square 멤버쉽 퀴즈 3/3 만점자 - GIAI101: GIAI Square Membership Quiz (2025) | GIAI
- GIAI Square 가입에 썼던 이메일 주소로 [email protected]에 제목 형식을 '[설명회 참석] 이름 및 간단 소개'으로 한 이메일을 통해 온/오프 중 참석 희망 여부 표현
온라인 진행을 원칙으로 하고, 오프라인으로 참석할 시에는 SIAI 달력, 동/하계 티셔츠, 컵 같은 기념품을 지급해드리려고 합니다.
저 퀴즈는 3문제 중 1문제도 못 맞추는 경우가 많기 때문에, 가능하면 아래의 Cheat sheet을 여러 번 읽어보고 준비가 됐다 싶을 때 도전하시는 것을 추천드립니다
GIAI Square는 GIAI 본사 팀과 합의해서 만든 커뮤니티인데, 그간 경험을 바탕으로 고급 지식에 대한 이해도, 습득력, 문장 이해력 등을 두루두루 갖춘 인력들에게만 게시판을 열자는 목적에서 Quiz를 만들었습니다. 저 퀴즈 3문제 중 2문제 이상 맞춘 인력들에게만 커뮤니티에 글을 등록할 수 있도록 권한이 업그레이드 됩니다. 문제를 만들 때부터 이미 저 문제를 자기 힘으로 풀어내는 인력이 거의 없을 것이다는 것을 알고 만든 만큼, Cheat sheet을 읽고 이해할 수 있으면 토론 자격이 있다고 인정해주려고 합니다. 지난 7년간 한국 사회에서의 경험상, 이렇게 답안지에 해당하는 자료를 줘도 저 문턱을 넘어오는 사람이 거의 없을 것이라고 예상하는 중인데, SIAI에 입학할 수 있는 최소한 요건도 같다고 보고 만들었습니다. 모르는 것은 어쩔 수 없지만 기회를 줬을 때 학습할 수 있는 의지, 끈기, 기초 역량은 갖추고 있어야 고급 교육을 받을 수 있고, 그런 대화를 나눌 수 있다고 생각하기 때문입니다.
장기적으로는 GIAI에서 운영 중인 언론사 기사, 블로그 기고 글, SIAI 입시 관련 Q&A 등의 모든 대외소통을 GIAI Square에서 할려는 것으로 알고 있습니다.
+2월 21일 추가
아래는 퀴즈에 참석했던 분이 보내주신 메일의 일부입니다
퀴즈 3문제를 모두 맞춘 뒤 메일 보냅니다. 퀴즈가 어려울까봐 걱정했는데 정말 최소한의 노력과 성의를 보여라 정도의 난이도여서 안심(?)하며 응시했네요.
그간 글로벌 팀원들 사이에서 너무 어려운 퀴즈로 사람들을 쫓아내는게 아니냐는 말도 있었는데, 기대했던대로 Cheat sheet을 꼼꼼하게 읽은 분들은 쉽게 그 벽을 넘어선 것 같아서 안심해도 될 것 같습니다.
SIAI 공식 운영은 모두 GIAI로 이전
SIAI 설립하고 약 4년 간, 더 멀리는 한국 귀국 후 AI/Data Science 교육 했던 기간을 포함해서 약 7년 간의 경험을 미뤄봤을 때, SIAI 교육을 따라올 수 있는 한국인 학생이 거의 없을 것이라는 경험 기반의 확신을 얻었기 때문에, 한국 운영을 접는 것에 대한 아쉬움은 없습니다. 졸업 할 수 있는 실력이 안 되는 학생들에게 Business track이라는 학위 과정까지 만들면서 조직의 막대한 자원을 썼는데, 끝까지 고집을 피운 학생들에게 제가 더 미안해 할 필요는 없겠지요.
현실적으로 한국 학생들 대부분이 기초 수업을 최소한 재수강 이상 하며 긴 시간 반복 학습을 해야 겨우 글로벌 상위권 교육에서 말하는 '사고력'이 무엇인지 개념을 쫓아 갈 수 있다는 것을 몇 년간 봤습니다. '수학'이 아니라 '수학이라는 언어로 사고하는 훈련'을 강조했건만, '수학'만 강조하는 교육이라는 잘못된 평가가 붙었던 것도 한국 학생들의 인식과 글로벌 상위권 교육 사이의 격차가 컸기 때문일 겁니다. 앞으로 혹시라도 한국인을 가르쳐야 되면 글로벌 기준을 따라 가을에 학위 과정을 시작할 것이 아니라, 3월부터 4-5개월 간 미리 공부하고 8월 쯤에 입학 가능 여부를 가늠하는 시험을 치뤄서 조건부 입학을 시켜줘야겠다 싶습니다.
처음 SIAI 설립 무렵에는 MSc 과정만 그렇게 하면 될 것이라는 안이한 기대가 있었는데, 4년 간 운영해보니 학부 2학년 교육에 해당하는 MBA AI/BigData 교육의 초반부 조차도 일종의 '선수 학습' 개념으로 최소한 6개월 정도 훈련을 시켜야 할 것으로 보입니다. 한국의 현실이 이렇더군요.
한국인이 한국인을 콕 찝어 차별하는 것 같아 미안한 마음이 크지만, 조사해보니 신촌의 S모 명문 대학교가 영국 모 대학과 제휴를 맺고 학부 과정 몇몇 전공에 대해 공동 학위 과정을 운영하면서 한국 학생들을 6개월에서 1년간 교육 시킨 다음에 영국으로 보냈던 기록이 있더군요. 양국 간의 학제가 달라 세부적으로 차이가 있긴 하겠지만, 한국 학생들이 기초 역량 부족으로 좌절하는 경우가 매우 많았기 때문에 만들어진 보조 과정 역할을 했던 것으로 전해 들었습니다.
강의 노트와 시험 문제 일부를 SIAI 학생들 대상 교육 콘텐츠 페이지 (SIAI SIS)에 공개 설정으로 풀어놓은 만큼, 꼭 SIAI에 오지 않더라도 글로벌 명문대에서 AI/Data Science를 공부하고 싶은 학생들이 '수학 지식'이 아니라 '사고력'을 길러주는 훈련, '수학이라는 언어'를 활용해 '사고'하는 훈련, 그래서 배운 지식을 현장에 응용하는 훈련을 미리 보고 준비하는데 도움이 됐으면 합니다.
- Modeling Joint Distribution Of Monthly Energy Uses In Individual Urban Buildings For A Year | Global Institute of Artificial Intelligence
- Sleep State Detection Method by Data-generated likelihood | Global Institute of Artificial Intelligence
위는 그렇게 사고하는 훈련을 받고 자기 힘으로 논문 쓰는 능력을 길러낸 학생들의 자랑스러운 논문들 입니다. Google Scholar에서 바로 검색이 되는 걸 보면서 뿌듯했는데, 그런 고급 논문을 그런 학생을 길러낼 수 있어서 행복한 시간이었고, 그런 학생들과 인연이 닿아서 감사할 따름입니다.
Picture
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.



[공지] GIAI 통합 진행 중 업무 시스템 개편
[공지] GIAI 통합 진행 중 업무 시스템 개편
Picture

Real name
TER Editors
Bio
The Economy Research (TER) Editor
Published

GIAI와 한국 지사 간의 협업 강화를 위해 당사 업무 시스템이 아래와 같이 통합 개편됩니다.
- 작업플랫폼 이전
- 콘텐츠 플랫폼 이전
- 강의 관리 플랫폼 이전
- 기업/학교 인사 관리 플랫폼 이전
업무 시스템 개편은 한국 지사의 GIAI 매각과 관련된 사안 중 일부로, 기존 서비스 이용자 분들 중 관련 항목이 있으신 분들은 참고하시기 바랍니다.
1.작업 플랫폼 이전
2024년 12월 1일부터 Microsoft Teams 기반의 업무 중심 시스템을 NextCloud 기반으로 변경하게 되었습니다. 당사의 스위스 대학 교육 서비스인 SIAI를 통해 이미 Microsoft 365 for Education에 기반한 계정 관리 및 Office 이용 방식은 변함이 없습니다만, 내부 보안 강화, 데이터 관리 강화, 서비스 연동 강화 등의 목적을 위해 유럽에서 가장 강력한 오픈 소스 협업 도구인 NextCloud를 쓰기로 결정했습니다.
SIAI 재학생 관리 또한 NextCloud 기반으로 이전됩니다.
이미 Teams 채널 이용은 중단된 상태입니다만, 기존 SIAI 재학생들 중 학업을 일시 중단했던 학생들의 플랫폼 이전을 지원하기 위해 Microsoft Teams 채널은 2025년 3분기 말에 End of Life (EoL)가 예정되어 있습니다.
2.콘텐츠 플랫폼 이전
지난 2024년 11월 1일부터 기존의 WordPress 시스템을 Drupal 기반의 콘텐츠 관리 시스템(CMS)으로 변경했습니다. 아직 완전히 이전되지 않은 서비스들이 있습니다만, 법인 소유권 정리가 완료되는 2025년 3월말까지 모든 콘텐츠가 Drupal 기반의 신규 시스템으로 이전될 에정입니다.
이를 바탕으로 글로벌 시장에서 가장 활발하게 쓰이는 포럼 플랫폼 중 하나인 Discourse와 이번에 이전하는 Drupal을 연동해 당사의 언론 기사, 블로그 포스팅, 외부 공개 강의 및 기타 콘텐츠에 대한 토론 플랫폼을 준비 중에 있습니다. Discourse의 포럼으로 CMS의 댓글 시스템을 돌리는 방식으로 개발이 진행 중이고, 개발 작업이 완성되면 기사의 댓글이 포럼의 콘텐츠가 되는 방식으로 서비스가 될 예정입니다. 2025년 1분기에 베타버전, 2분기부터는 정식 버전을 출시하는 것을 목표로 진행 중입니다.
- GIAI Square: https://sq.giai.org
따라서 2025년 1분기 중에 저희 GIAI (및 GIAI Korea) 산하 웹사이트 방문자들 간에 댓글 및 포럼을 통한 의사소통이 진행될 수 있을 것으로 보입니다. 포럼 서비스 명칭 및 전용 URL은 위와 같습니다.
3.강의 관리 플랫폼 이전
위의 1항에서 언급된 서비스 이전에 따라 Microsoft 365 for Education 기반의 교육 관리 시스템(LMS)도 이전합니다. 글로벌 시장에서 가장 널리 알려진 교육용 오픈 소스 중 하나인 Moodle을 기반으로 제작되었고, SIAI 재학생에 대한 교육 시스템 이전과 더불어, 학위 외 과정에 대한 직업 학교(Vocational school) 교육을 담당하는 GIAI LMS를 제작 중에 있습니다.
- SIAI LMS: https://lms.siai.org
- GIAI LMS: https://lms.giai.org
GIAI LMS에서는 SIAI 입학 시험과 더불어 GIAI 소속 서비스 및 관계사 들에서 개별적으로 강의 콘텐츠를 운영합니다. GIAI 소속 서비스로는 SIAI 입학 시험(유료), SIAI 입학 전 기초 수학 수업(무료) 등이 제공되고, 관계사인 MDSA에서는 AI/Data Science 기반 논문 해석, EduTimes에서는 미국 대학 입학 컨설팅 등을 각 사 재량에 맞춰 제공할 예정에 있습니다.
교육 내용에 대한 궁금증, 토론 등이 필요한 경우도 위의 GIAI Square에서 진행해 활발한 의사소통을 돕는 것을 목표로 하고 있습니다.
안타깝게도 모든 콘텐츠가 영어로 제작·운영될 예정이고 관리 인원 부족 등의 이유로 댓글 기능을 제외한 한국어 시스템 지원은 어려울 것으로 예상됩니다.
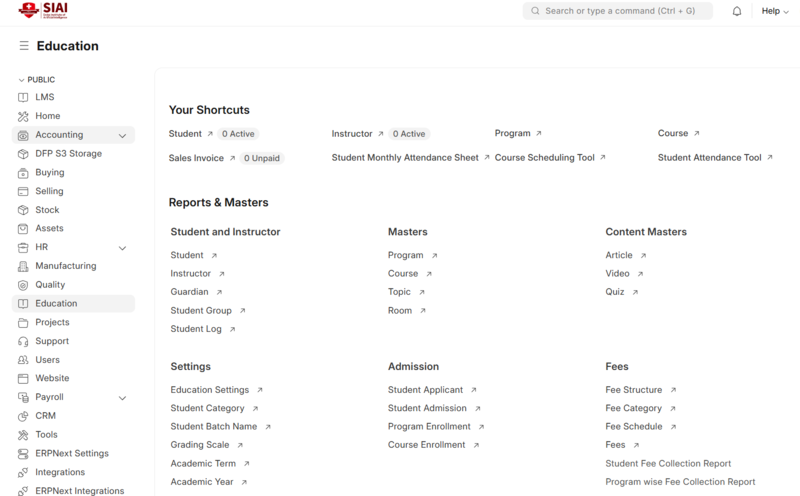
4.기업/학교 인사 관리 시스템 이전
GIAI의 인사 관리 시스템을 바탕으로 SIAI의 학생 관리 시스템을 새롭게 제작했습니다. 2025학년도 SIAI 지원자부터는 GIAI에서 입사자 신규 관리에 쓰이는 ERP 시스템을 바탕으로 신입생 지원, 입학 시험, 학생 관리 등이 진행됩니다.
기 공지한대로 2025년 1분기까지 국내에서는 The Economy Korea를 제외한 국내 서비스가 모두 GIAI 본사로 이전됩니다. 더불어 The Economy Korea 기자 개인 정보, SIAI 현재 재학생 및 졸업생 데이터를 제외한 모든 국내 서비스 이용자 데이터는 삭제 처리 됩니다.
감사합니다
GIAI Korea
Picture
Real name
TER Editors
Bio
The Economy Research (TER) Editor
[공지] 회사 매각, 사명 변경, CI변경 및 서비스 이관 (종합)
[공지] 회사 매각, 사명 변경, CI변경 및 서비스 이관 (종합)
Picture
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Published

지난 4월부터 진행된 회사 매각, 사명 변경, CI변경 및 서비스 이관 관련된 영문 공지들을 종합하고 최근 결정 사항을 반영한 한국어 공지입니다.
당사는 2025년 3월 말 완료를 목표로 지난 2024년 4월부터 회사 매각에 따른 법적 절차를 진행 중에 있습니다. 인수자는 유럽에서 운영 중인 학술 연구 모임인 GIAI (Global Institute of Artificial Intelligence) 입니다. 이번 매각은 국내에 '스위스AI대학'으로 알려진 SIAI (Swiss Institute of Artificial Intelligence) 설립 당시에 이미 논의됐던 사안으로, SIAI의 소유권이 GIAI로 이관되는 중에 한국 기업 명칭도 함께 변경되었습니다. 지난 7월 1일부로 변경된 한국 자회사의 공식 명칭은 GIAI Korea Inc. 입니다.
회사 매각과 관련해 아래의 사항들이 변경됩니다
1.전문지 서비스의 글로벌 동조화
첫째, 국내에서 운영 중이던 한국어 전문지들은 GIAI 산하의 경제 연구소 The Economy(https://economy.ac) 산하의 경제지에 편입됩니다. 지난 4월부터 단계적으로 명칭 변경이 있었고, 최근까지 GIAI 산하의 서비스들과 동조화가 진행되었습니다. 구조는 아래와 같습니다.
- 글로벌 본사
- Global Institute of Aritificial Intelligence (https://giai.org) - AI/Data Science 협회
- The Economy Research (https://economy.ac) - GIAI 산하 경제연구소
- The Economy News (https://news.economy.ac) - 연구소 산하 경제 전문지
- 한국 운영
- GIAI Korea (https://kr.giai.org) - GIAI Research (https://giai.org/researches)의 한국어 버전
- The Economy Korea (https://kr.giai.org) - 국내 경제지 통합 포털
- 파이낸셜 이코노미 (https://financial.economy.ac)
- 테크 이코노미 (https://tech.economy.ac)
- 폴리시 이코노미 (https://policy.economy.ac)
지난해까지 PDSI 이름으로 제공되었던 AI/Data Science 블로그 콘텐츠들 중 일부는 GIAI 운영 방침에 맞게 수정해 GIAI Research (https://giai.org/researches)에 영문 기고 글로 등록 중에 있습니다. 국내 공유가 필요하다고 판단되는 콘텐츠는 GIAI Korea (https://kr.giai.org)에 번역 담당 기자 분들이 옮겨놓고 있으니 영어가 불편한 분들께 도움이 되었으면 합니다.
2.스위스 AI대학 운영 주체 변경
SIAI 운영 및 소유권과 관련해서는 지난 2022학년도 입학 기수의 2024년 9월 졸업, 내년 3월에 예정된 SIAI의 대학 교육 인가 연장 작업, 내년 9월에 예정된 한국 학생들 졸업 지원 등의 일부 잔여 업무를 제외하고 SIAI 운영을 GIAI 이사회에 이관하기로 합의했습니다. 2024년 겨울부터 진행되는 2025학년도 입시는 GIAI Korea의 운영 노하우를 GIAI 이사회에 전달하는 방식으로 운영 후, 2026학년도부터는 완전 이관이 예정되어 있습니다.
지난 3년간 한국의 열정 넘치는 학생들을 통해 검증된 고급 AI/Data Science 교육이 GIAI의 손에서 글로벌 시장에 널리 확대되기를 바랍니다.
3.글로벌AI협회(GIAI) 간단 소개
SIAI 설립 당시였던 2021년 여름부터 GIAI가 현재 진행하는 AI/Data Science 관련 연구 사업을 담당하는 기관 설립에 대한 논의가 상당히 진행되었습니다. 당초에는 SIAI 교육을 통해 훈련된 다수의 인력들을 GIAI에서 활용하는 방안이 있었기 때문에 SIAI 설립이 선순위로 진행되었습니다만, 안타깝게도 GIAI의 Research 팀이 원하는 인력을 단 시간에 훈련시키기는 어려웠던 것 같습니다.
GIAI에서는 SIAI를 통한 대학 수준의 고등 교육과 더불어, SIAI 입학 시험을 포함한 비학위 과정으로 AI/Data Science 교육을 관리하는 GIAI Square가 커뮤니티 형태로 운영 중입니다. GIAI 이사회의 결정으로 지난 4월부터 단계적으로 SIAI 교육 자료를 정리한 AI/DS 교과서 서비스를 제공하고 있기도 합니다.
이어 글로벌 교육 전문지인 EduTimes와 협력해 MBA Ranking, Law School Ranking 등의 서비스를 공동으로 관리 중입니다. 기존 대학들의 랭킹 시스템이 가진 문제를 개선하고자 빅데이터(BigData) 기반의 데이터를 네트워크 구조로 재편한 시스템을 통해 랭킹을 추출하는 서비스를 제공합니다. 더불어 경제 전문지 운영에 있어서도 EduTimes의 언론사 운영 노하우를 참고하고 있습니다.
그 외 AI/Data Science 기반의 금융 서비스를 위해 각종 연구를 진행하고 있고, 전술한 전문지 관리 효율화를 위해 '대형언어모델(LLM)'의 영문 버전을 고도화하고 있기도 합니다.
GIAI 산하에서 운영 중인 경제 연구소(The Economy)는 EduTimes와 협력 아래 영문 전문지(https://news.economy.ac)와 한글 전문지(https://kr.giai.org)를 운영 중입니다. GIAI는 랭킹 알고리즘 및 LLM 모델 고도화 서비스를 제공하고 있고, EduTimes는 언론사 운영 역량을 공유하고 있습니다. 저희 GIAI Korea는 GIAI로 편입되면서 GIAI 와 EduTimes가 공동으로 운영하던 전문지의 국내 라이선스를 확보하게 됐습니다.
4.향후 운영 방침
당사의 소유·지배 구조가 대대적으로 변경되면서 향후 조직 운영 방향에 대해서도 고민이 많았습니다. 지난 6년간 한국에서 데이터 과학 기반의 IT사업을 해보기 위해 수 많은 시도를 하며 깨닫게 된 것 중 하나는, 제가 아무리 노력해도 바뀌지 않으려는 관성과 고집 속에 살고 있는 절대 다수를 바꿀 수는 없다는 것이었습니다. 그들을 바꾸지 못하면 성공할 수 없는 사업을 굳이 붙잡고 있지 말고, 제가 만드려는 상품의 가치를 이해하고 그 도전에 막대한 비용을 선뜻 지불하려는 의향을 갖춘 이들과 꿈을 실현하는 것이 맞겠다고 마음을 바꿔 먹었습니다. 보잘 것 없는 재능이지만, 그 재능을 살려줄 수 있는 자본과 인력이 있는 곳이어야 조금이라도 더 성공 가능성을 높일 수 있을 것이라는 아픈 지적에 동의했기 때문입니다. 지난 수천년간 이 땅에서 도전의 날개를 펴지 못했던 선각자 분들도 시대와, 배경과, 주제만 다를 뿐, 크게 다르지 않은 경험을 겪으셨으리라 생각합니다.
GIAI Korea는 2025년 9월 졸업 예정인 SIAI 한국인 학생들 관리를 제외하면 한국 내에서는 한국어 전문지만 운영할 예정입니다. 고급 AI교육의 가치에 대한 이해도가 부족한 것만큼이나 고급 경제지에 대한 소비 수준이 낮은 시장에 굳이 시간을 쓸 필요는 없다는 불투명한 확신에 매일같이 선명도가 더해지고 있습니다만, 그래도 이렇게 시장의 교육 수준을 끌어올리는 콘텐츠를 부워 넣다보면 언젠가는 제 도전을 다시 펼칠 수 있을지도 모른다는 미련의 증거인 것 같아 한편으로는 부끄럽습니다. 다만 언론 서비스 쪽은 시스템이 구축되어 제 업무가 별로 없는만큼, 당분간은 내적 갈등을 붙잡고 있을 예정입니다. 이제 한국 업무가 최소화되는만큼 오랜 시간 Bucket list에만 넣어놨던 연구 주제들을 GIAI의 Research 팀과 함께 다시 꺼내 들겠습니다. 내년 하반기까지는 학생 선발 및 운영 경험을 GIAI 이사회와 공유하는데 시간을 쓰겠지만, 지난해부터 GIAI 연구진과 함께 자사 서비스에 실험 중인 다국어 번역 서비스, 사용자 반응 기반 각종 랭킹 서비스 등을 비롯해 AI/Data Science 지식을 활용해 사회 문제를 개선하는 연구에 좀 더 집중할 예정입니다.
그동안 여러분의 응원이 있어 여기까지 올 수 있었습니다.
감사합니다
Keith Lee, Head of GIAI Korea
Picture
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
비교우위론과 콥 더글라스 생산함수로 해석하는 미・중 갈등
비교우위론과 콥 더글라스 생산함수로 해석하는 미・중 갈등
Picture
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Input
최근 미・중 갈등이 심화되고 있다. 지난 2018년 시작된 트럼프 행정부의 대(對)중 무역 견제를 필두로 2021년 집권한 바이든 행정부에 들어서는 초당적 인프라법, 반도체 및 과학법 통과 등 제조업 중심의 내수 회복 및 중국 ‘옥죄기’를 목표로 파격적인 행보를 이어가고 있다. 이에 따라 글로벌 산업 구조가 재편되는 분위기다.
한때 독보적이었던 미국 제조업은 달러 기축통화로 ‘트리핀의 딜레마(Triffin’s Dillema)’ 및 글로벌 경쟁에 밀려 쇠퇴해 갔다. 하지만 최근 일련의 미・중 ‘디커플링(Decoupling・두 집단 간의 유사한 움직임이 사라지는 것)’으로 양국 간 자본력과 노동력의 비교우위(Comparative Advantage)가 뒤바뀌면서 미국 제조업은 고용률이 껑충 뛰는 등 부활의 움직임을 보이고 있다. 이와는 대조적으로 폭발적인 성장을 일궈냈던 중국 제조업은 미국의 공격적인 무역 제재로 인해 위축되고 있다. 하지만 미국의 IT, 금융업계는 정리해고 ‘칼바람’이 불면서 동종 업계 종사자들에게 싸늘한 소식을 알리고 있다.
본 칼럼은 경제학의 비교우위론을 개량한 무역 이론인 ‘헥셔-올린 정리’, 미시경제학의 수학적 도구인 ‘콥-더글러스 생산함수’, 통계학의 ‘회귀분석’을 적용해 새롭게 재편되고 있는 미국과 중국의 산업 구조를 재해석해 본다.
헥셔-올린 정리와 콥-더글라스 생산함수
미・중 갈등을 살펴보기 전에, 우선 해석을 도와줄 이론적 도구를 소개한다. 먼저 헥셔-올린 정리란 무역 당사국 간 생산요소와 부존량의 차이가 존재하고, 생산물마다 투입되는 요소집약도가 달라 무역이 이루어진다는 국제경제학 이론이다. 헥셔-올린 정리는 데이비드 리카도(David Ricardo)의 비교우위론에서 아이디어를 빌렸고, 관점을 살짝 비틀었다. 비교우위론은 국가의 기술력이 달라 비교우위가 발생한다고 본다. 반면 헥셔-올린 정리는 국가가 가진 노동(L)과 자본(K) 등의 요소집약도, 즉 재화를 생산하는 데 사용되는 생산요소의 양이 달라 비교우위 및 무역이 발생한다고 본다. 예를 들어 중국은 상대적으로 노동이 풍부하고, 미국은 자본력과 기술이 풍부하다. 따라서 각국은 노동집약적 상품과 자본집약적 상품을 서로 교환한다.
헥셔-올린 정리를 수식으로 나타내면, 경제학에서 주로 사용하는 콥-더글러스 생산함수 형태로 표현할 수 있다. 이 함수는 생산요소(L, K) 집약도와 생산산출물(Y) 간의 관계를 나타내며 국가나 특정 산업에서 노동과 자본이 투입됐을 때, 얼마만큼의 요소 생산성을 가져다주는지 분석하는 데 널리 활용된다.
회귀분석으로 콥-더글라스 생산 함수의 ‘탄력성’ 추정
한 국가의 총 생산량을 $Y_i$, 노동 투입을 $L_i$, 자본투입을 $K_i$, 그 외 노동력과 자본력으로 설명하지 못하는 생산량의 나머지(잔차)를 $exp(u)$로 하는 콥-더글라스 함수를 아래와 같이 세워보자.
\[
Y = exp(\beta_0) \cdot L^{\beta_L} \cdot K^{\beta_K} \cdot exp(u) \quad \cdots ~(1)
\]
콥-더글라스 생산함수에서 ‘탄력성’ 또는 ‘요소 생산성’이란 $\beta_L$과 $\beta_K$로 표현되는데, 이는 약간의 식 변형을 통해 쉽게 추정할 수 있다. 먼저 식 1 양변에 로그를 취하면 식 2로 바뀐다.
\[
\log{Y} = \beta_0 + {\beta_L} \log{L_i} + {\beta_K} \log{K_i} + u \quad \cdots ~(2)
\]
식 2는 어디서 많이 본 형태다. $\log{Y}$를 종속변수, $\log{L}$, $\log{K}$를 독립변수로 한 선형 회귀식이다. 이때 $\log{L}$과 $\log{K}$를 편미분하면 $\beta_L$과 $\beta_K$를 얻을 수 있는데, 미시경제학에서는 이 회귀 계수들을 ‘생산요소의 대체탄력성(Elasticity of Substitution, $e_{LY}$, $e_{KY}$)’이라고 부른다.
\begin{align*}
\beta_L &= \cfrac{\partial \log{Y}}{\partial \log{L}} = \cfrac{dY}{Y}*\cfrac{L}{dL} = \cfrac{dY/Y}{dL/L} = e_{LY} \\
\beta_K &= \cfrac{\partial \log{Y}}{\partial \log{K}} = \cfrac{dY}{Y}*\cfrac{K}{dK} = \cfrac{dY/Y}{dK/K} = e_{KY}
\end{align*}
식 2에서 OLS(Ordinary Least Square) 추정을 통해 $\beta_L$과 $\beta_K$를 구하면 노동과 자본을 추가로 투입했을 때, 특정 국가의 생산량이 얼마만큼 탄력적으로 증가하는지 정량적으로 분석할 수 있게 된 것이다.
국가 간 콥-더글러스 생산함수의 회귀 계수 차이에 따른 무역 발생
지금까지 논의를 정리하면 우리는 콥-더글라스 생산함수의 $\beta_L$, $\beta_K$를 추정함으로써 각국의 노동생산성과 자본생산성을 정량적으로 파악할 수 있고, 이 콥-더글러스 생산함수를 기반으로 각국 간 무역의 발생 원인을 헥셔-올린 정리로 설명할 수 있다.
예를 들어 한국은 상대적으로 자본이 풍부하고 칠레는 노동이 풍부하다고 가정해 보자. 이때 스마트폰은 노동보다는 자본이 많이 투입되는 자본집약적 재화며, 와인은 자본보다는 노동이 많이 투입되는 노동집약적 재화라고 하자. 그렇다면 스마트폰 생산량에 있어서는 $\beta_K$가 $\beta_L$보다 크며, 와인 생산량에 있어서는 $\beta_L$이 $\beta_K$보다 클 것이다. 헥셔-올린 정리에 의하면, 요소집약도($\beta_L$, $\beta_K$)의 차이로 우리나라는 자본집약적인 스마트폰을 더 싸게 생산하고, 칠레는 노동집약적인 와인을 싸게 생산하는 ‘비교우위’가 발생해 무역이 일어난다고 이해할 수 있다.
여기까지 하면 분석에 필요한 도구들은 모두 준비됐다. 바로 분석에 들어가기보다는 미・중 갈등으로 양국의 산업 구도가 바뀐 최근 양상을 먼저 알아보자.
중국을 염두에 둔 미국 행정부의 ‘자급자족’ 움직임에 미국 제조업 고용률 고스란히 증가해
미국의 수출 기반 산업, 그중에서도 제조업은 1970년대 중후반 시작된 페트로 달러(petro-dollar) 체제로 인해 꾸준히 무역 적자를 기록했고 점차 쇠퇴해 갔다. 여기에 로널드 레이건 집권 시절인 1980년대 잇따른 석유 파동으로 내수 경기 침체가 맞물리면서 노동집약적 상품 중심의 제조업은 더욱 가파르게 몰락해 갔다. 이를 타개하기 위해 정부는 세금 감면, 공적 자금 지출, 막대한 국방비 지출 등으로 경기 침체를 극적으로 진압했다. 이후 미국은 약 40년간 낮은 금리 기조와 저인플레이션을 경험하며, COVID-19 팬데믹이 일어나기 전까지 미국의 제조업 고용률은 꾸준히 회복되고 있었다.
그러나 COVID-19 발발 여파로 또다시 경기가 위축되면서 주요 자동차 제조업체의 조립 공장이 폐쇄되고 대리점이 문을 닫는 등 자동차 제조가 하룻밤 사이에 중단됐다. 또한 식품 산업에서도 노동자들이 코로나에 걸리고 사망했다는 사건이 연달아 뉴스에 보도되면서 식품 공장도 가동을 중단하고 수많은 노동자가 대거 일자리를 잃게 됐다. 여기서 미국 행정부는 4조 5,000억 달러라는 대규모 양적완화를 단행하면서 고용률을 끌어올렸고, 제조업계도 되살아나기 시작했다.
이러던 중 미국은 바이든 대통령의 선두 지휘하에 초당적 인프라 투자법안(BIL)과 반도체 및 과학법(CHIPS and Science Act)을 대대적으로 추진했다. 이를 통해 교량, 도로, 농촌 지역을 전반적으로 재정비하는 등 미국의 내수를 튼튼히 다졌다. 그 효과로 4차 산업혁명의 꽃인 반도체 산업에서 중국의 반도체 산업 성장을 꺾는 것은 물론, 현재 미국은 글로벌 반도체 산업의 판도를 미국 중심으로 재편하려는 움직임을 보인다.
이러한 정치적 배경에 탄력받은 제조업은 연이은 상승 추세를 타게 된다. 실제로 파이낸스 타임즈에 따르면 지난 6월 기준 바이든 집권 이후 미국 제조업 고용은 집권 전보다 대략 80만 명 가까이 증가했으며, 약 1,300만 명이 제조업에 종사하고 있는 것으로 집계됐다. 이는 2008년 글로벌 금융위기 이후 가장 높은 수치다. 그림 1을 보면 코로나 시기에 양적완화, 초당적 인프라법, 반도체 및 과학법 추진 시기에 발맞춰 고용률이 가파르게 상승한 것을 확인할 수 있다.
울고 있는 미국 금융업계와 테크 기업
이처럼 본격적으로 이륙 준비를 하는 제조업과는 대조적으로 미국 빅테크 기업들은 지난 하반기부터 대규모 감원이 이루어지고 있다. 아마존, 메타를 포함한 유수 글로벌 IT 기업들의 고용 축소를 필두로 상당수 미국 테크 기업이 감원에 동참하고 있다. 미국 IT 업계 정리해고 추적사이트 ‘레이오프(Layoffs.fyi)’에 따르면 지난해만 1,058개 IT 기업에서 16만 4,709명의 직원이 해고됐다. 특히 지난해 11월 아마존은 1만 명, 메타는 1만 1,000명을 해고했다.
빅테크 기업의 감원은 올해도 지속되고 있다. 지난해에 이어 아마존은 올해만 1만 7,000명을 추가로 해고했다. 애플은 운영 예산을 절감하면서 구조조정은 피하겠다고 발표했으나, 일부 외신에 따르면 올해 4월 캘리포니아에 거점을 둔 미국 본사의 소매팀부터 인력 감축이 시작된 것으로 알려졌다.
한편 미국 금융업계에서도 칼바람을 피하지 못한 것으로 보인다. 지난 5월 미국 경제 뉴스 채널 CNBC는 모건스탠리, 뱅크 오브 아메리카, 씨티그룹 등의 유수 월스트리트 투자은행이 대규모 감원을 진행했다고 밝혔다. 모건스탠리는 6월 말까지 약 3,000명을 해고했으며 이는 뉴욕에 기반을 둔 총 은행 인력의 5%에 해당하는 수치다. 아울러 씨티그룹, 뱅크 오브 아메리카도 지난 5월 수백 명의 직원을 해고하면서 금융업계에 싸늘한 소식을 알렸다.
미-중 ‘디커플링’에 추락하는 중국 제조업
한편 미국과 직접적인 패권 마찰을 빚고 있는 중국은 제조업에서 상당한 출혈을 감수하고 있다. 앞서 살펴봤던 바이든 행정부의 내수 증진을 위한 초당적 인프라법, 반도체 및 과학법과 같은 대(對)중국 기술 제재 강화와 함께, 기존 불거져 왔던 두 국가 간 관세 분쟁이 맞물리면서 미-중 간 ‘디커플링’이 본격적으로 심화되고 있기 때문이다.
미국과의 지정학적 충돌로 중국의 제조업 성장세는 상당히 위축됐다. 그림 2를 보면 미국이 내수 경쟁력 확보, 즉 자급자족하고자 초당적 인프라법을 일부 시행하기 시작한 시점인 2021년부터 중국의 2차 산업(제조업 관련)의 성장률이 감소세로 접어들게 된 것을 확인할 수 있다.
같은 맥락으로 지난 7월 13일 중국 해관총서(관세청)이 발표한 자료에 따르면 중국의 6월 수출액은 2,853억 달러(약 361조원)로 전년 동월 대비 12.4% 감소했다. 이는 -7.5%를 기록했던 지난달과 시장 예상치 -9.5%를 모두 밑돈 수준이다.
헥셔-올린 정리에 입각한 미-중 갈등 해석
지금까지의 논의를 통해 미국과 중국 간 ‘자급자족’ 및 ‘디커플링’ 등의 국가적 움직임이 본격화된 2021년과 2022년 사이에 미국과 중국은 제조업에서 상반된 행보를 보이기 시작했다. 또한 미국의 월스트리트, 빅테크 기업은 정리해고의 그림자가 드리우는 등 금융・IT 업계가 전반적으로 위축되고 있는 것을 살펴봤다.
여기서 한 가지 의문을 제기할 수 있다. 미국과 중국의 산업 구조 변화는 왜 반대로 이뤄진 걸까? 예컨대 미국의 대(對)중 의존도 감소를 위한 초당적 인프라법, 반도체 및 과학법은 왜 미국의 제조업을 부흥시키고, 중국의 제조업은 쇠퇴하게 된 걸까? 미국이 내수를 다지기로 했을 때, 미국과 중국의 제조업이 함께 올라갈 수는 없었을까? 그리고 생뚱맞게 왜 미국 금융・IT 업계는 위축된 걸까?
헥셔-올린 정리로 미-중 갈등과 산업 구조 변화의 패러다임을 바라보자. 1970년부터 2022년까지 미국은 달러 기축통화로 제조업 기반 수출 경쟁력이 약해져 금융업과 IT 등 자본집약적 산업에 집중해왔다. 물론 이 과정에서 기축통화국으로서 글로벌 자본이 미국으로 흘러왔던 것이 중요 요인이라는 점도 부정할 수 없다. 이 시기에 미국은 중국에 비해 ‘기술력’ 또는 ‘자본력’에 비교우위가 있었고, 반대로 중국은 값싼 노동력을 내세워 1차 산업 기반의 노동집약적 산업에 집중했기에 ‘노동력’에 비교우위가 있었던 것으로 해석할 수 있다. 이렇게 ‘각자 잘하는 것’에 집중한 미국과 중국은 서로 기술집약적 생산품과 노동집약적 생산품을 무역으로 교환함으로써 국가를 성장시켰다.
그러나 최근 초당적 인프라법, 반도체 및 과학법 등의 법안이 통과되는 등 미-중 기술 경쟁이 본격화되면서 미국 제조업이 상승 기류를 타게 됐다. 게다가 미국에서 노동력이 싸지면서 미국과 중국 간 비교우위가 변하기 시작했다. 미국은 자본력 대비 노동력의 상대가격이 점차 하락하면서 자원을 조금씩 제조업으로 옮겼다. 이에 따라 자연스럽게 자본 중심 산업인 금융과 IT 업계는 노동 투입이 빠지고 있는 것이다. 한편 중국은 이와는 대조적으로 미국의 공격적인 제재로 인해 노동 중심 산업인 제조업이 위축되면서 자본력 대비 노동력의 상대가격이 비싸지고 있다고 해석할 수 있다.
콥-더글라스 생산함수의 회귀 계수 차이에 따른 미・중 산업 구도 변화
이번에는 콥-더글라스 생산함수의 요소생산성(탄력성)을 기반으로 미-중 갈등을 다시 비춰보자. 한 국가의 총생산량을 $Y_i$, 노동 투입을 $L_i$, 자본 투입을 $K_i$, 그 외 노동력과 자본력으로 설명하지 못하는 생산량의 나머지(잔차)를 $exp(u)$로 하는 콥-더글라스 함수는 아래와 같다. 이때 국가 $i$는 미국 U, 중국 C 두 개만 존재한다고 가정한다.
\[
Y = exp(\beta_0) \cdot L^{\beta_L} \cdot K^{\beta_K} \cdot exp(u)
\]
페트로 체제 시행으로 대규모 무역 적자가 나기 이전인 1980년대 이전까지의 미국은 $\beta_L^U$과 $\beta_K^U$가 모두 중국보다 높았을 것이다. 그 이유는 2차 산업 중심인 제조업의 왕성한 경제 활동을 위시했던 미국은 당시 1차 산업(경공업) 중심으로 경제 성장에 박차를 가했던 중국보다 노동생산성도 높았을 것이다. 또한 당시 미국은 기계화, 자동화 등의 자본 투자를 통해 생산성을 크게 높였기 때문에, 수공업 중심이었던 중국 대비 자본생산성도 높았을 것으로 짐작된다.
한편 1980년대 이후부터 코로나 발발 이전으로 가면, 미국은 페트로 체제하에 제조업이 쇠퇴하는 길을 걷었고, 반면 중국은 끊임없는 시장 개혁, WTO 가입 등으로 폭발적인 성장을 거듭했다. 따라서 제조업에 한정해서 봤을 때 미국의 $\beta_L^U$과 $\beta_K^U$ 는 모두 중국보다 낮아졌을 것이다.
그러나 2021년과 2022년 사이에 미국이 중국을 견제하고자 초강수를 두면서 최근 들어 미국 제조업이 되살아나기 시작했고, 제조업에서 미국의 $\beta_L^U$과 $\beta_K^U$는 중국을 따라잡고 있는 것으로 분석된다.
여기에 헥셔-올린 정리를 얹어보면, 최근 미・중 갈등으로 인해 미국의 $\beta_L^U$과 $\beta_K^U$이 중국보다 절대 우위(Absolute advantage)가 있는 것은 물론, $\beta_L^U$
이 $\beta_K^U$보다 커지려고 하는 움직임이 보인다. 미국은 제조업으로 노동력이 옮겨가고 있으며 중국은 무역 제재로 인해 $\beta_L^C$가 줄어서 $\beta_K^C$가 상대적으로 커지고 있는 상황으로 해석할 수 있다.
Picture
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.


Section: Business
Section: Business
Picture
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Input
Picture
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
AI/Data Science 연구이야기
AI/Data Science 연구이야기
Picture
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Input
들어가며
국내 귀국해서 보면 'AI전문가' 혹은 '데이터 전문가'라고 스스로 주장하는 분들 중에
수학을 언어로 쓸 수 있는 분
들을 거의 찾아볼 수가 없습니다.
코딩이 언어지, 왜 수학이 언어냐, 수학이 왜 필요한지 이해를 못 하겠다는 반박을 하는 분들도 굉장히 많이 만납니다.
그런데, 'AI/Data Science 연구 이야기'를 다 읽고 나면 왜 제가 '수학을 언어'로 쓸 수 없는 분들을 AI/Data Science 관계자 취급조차 안 하는지 조금이나마 이해하게 되실 겁니다.
그 분들은 AI라고 이름 붙은 개발자 전용 Library (코드 묶음집)을 갖다 붙이는 IT개발자들이지, 'AI전문가' 혹은 '데이터 전문가'가 아니거든요.
간단한 예시를 하나 들어봅시다.
한 이커머스 스타트업이 시리즈 C 펀딩을 받으려고 하는 상황을 가정해 봅시다.
회사에서는 매주 목요일에 특별 할인 판매 이벤트를 여는데, 그 이벤트 때문에 아무래도 사용자가 많으니까, 그래서 웹사이트 서버 접속자 숫자가 평소보다 몇 배는 더 많으니까, 여기에 따른 비용 관리를 하고 싶어한다고 해 봅시다. 반대로 방문자 숫자가 많아야 시리즈 C 펀딩을 받을 때 아무래도 유리하니까, 한편으로는 더 공격적인 이벤트를 하고 싶고, 그래서 많은 방문자들을 감당할 수 있는 대형 서버를 운영하고 싶습니다. 비용이 더 나오기는 하겠지만, 일단 투자를 받는 게 중요하고, 시리즈 B 이전 투자자들은 시리즈 C에서 높은 밸류로 투자를 받기를 원할테니까요.
경영진의 머리 속에는 방문자 1명 당, 혹은 100명 당 자기들이 외칠 수 있는 밸류에이션 숫자, 투자 받기 전까지 남은 돈으로 감당할 수 있는 서버 비용, 투자 받기 전에 몇 달 동안 공격적인 이벤트를 해야 투자자를 설득할 수 있는 방문자를 뽑을 수 있을지 등등이 휙휙 지나갈 겁니다.
속칭 '통밥'으로 때려 맞출 수도 있지만, 'AI 전문가', '데이터 전문가'라는 사람이 좀 더 합리적인 수치를 뽑아내주면 더 신뢰감도 생기고, 투자사에 보여줄 때도 믿음직스럽겠죠?
이럴 때 각각의 집단 별로 어떤 식의 접근을 할지 한번 예상 시나리오를 그려보겠습니다.
AI/Data Science 연구 이야기 예시
방법 1. 전략 컨설팅 회사 출신
이 분들은 100명 일때 만원이면 10,000명 일 때 100만원이 된다고 생각하는 '선형(Linear) 사고'에서 크게 벗어나지 못하는 분들입니다.
서버가 감당하는 방문자 숫자라는게 AWS, Azure 같은 클라우드 서비스를 쓰고 있어도 비용이 선형으로 증가하는 일이 드뭅니다만, 이 분들은 방문자 숫자가 늘어나는 예상치에 맞춰 단순 곱하기로 비용 계산을 할 겁니다.
이미 Caching이 다 되어 있는 웹사이트를 단순히 보고 가는 거라면 Nginx만 돈다고 쳤을 때, CPU 코어 하나로 3,000개/초 정도의 트래픽을 감당하는 걸 제 간단한 서버로 점검을 해 본 적이 있습니다. 그런데 코어 2개가 되면 '6,000개/초'가 되느냐? 아뇨. 비선형(Non-linear)으로, 대부분 증가폭이 감소하는 Concave 함수 형태로 움직입니다. 하나의 서버에서 코어 숫자를 늘리느냐, 여러 서버로 분산해서 대응하느냐를 고민하기 시작해야죠.
방법 2. 개발자 출신
이런 지식이 있는 개발자 출신들은 서버를 N대로 분산하고, 그 앞에서 받아주는 Proxy 서버를 어떻게 구성해야하고, 그 때 추가 비용이 얼마나 발생하는지 등등을 자신있게 이야기 할 수 있을 겁니다.
Proxy 서버로 모든 트래픽을 받아서 뒤에 있는 Backend 서버에 넘겨주는 방식을 쓰고, 로그인 한 사용자들은 아무래도 CPU를 많이 쓰니까, CPU가 많이 붙은 서버로, 로그인을 하지 않은 일반 방문자들을 그 숫자가 많기는 하지만 Caching 된 페이지만 보다보니 정작 서버에 주는 부담이 적으니까, 가벼운 서버 N-k대에 나눠서 뿌려주는 서버 셋팅을 해 놓으면 아무래도 부담을 적절하게 나눠줄 수 있을 겁니다.
특히 로그인 한 사용자들은 뭔가 새로운 업데이트를 만들어 낼 가능성이 높으니, 로그인 서버를 주(Primary) 서버, 그 외 서버를 보조(Slavery) 서버로 만들면 좀 더 효과적으로 시스템 자원을 관리할 수 있겠죠.
이렇게 한 다음에, 개발자들은 '실험'을 해 봐야 얼마만큼의 트래픽을 감당할 수 있는지 알 수 있다고 주장할 겁니다.
그리고, 그 '실험'을 위해 사실상 위의 복잡한 서버 구조를 다 만들거나, 최소한 비슷하게라도 만드는데 많은 시간과 돈을 씁니다. 자칫 서버를 잘못 셋팅해서 갈아엎고 다시 셋팅하는 일도 종종 발생할 겁니다.
방법 1의 전략 컨설팅 회사 출신 입장에서는 속이 터질 겁니다. 고작 비용 하나 '통밥'으로 맞추려는데 이렇게 많은 비용을 추가로 써야 한다니?
그런데, 프론트 엔드 개발자가 웹페이지에 특정 요소를 빼면 더 많은 트래픽을 감당할 수 있다고 의견을 내고, 그걸 빼면 마케팅에 치명타라고 절대 안 된다고 홍보 팀이 반발하고, 화면의 딱 그 부분만 따로 독립 서버로 빼면 되지 않겠냐는 개발 팀장 급의 의견도 나오면서 회의가 산으로 가니, IT 개발을 하나도 모르는 전략 컨설팅 회사 출신 CEO는 미쳐나갈 것 같습니다.
이렇게 많은 시간과 비용을 쓰고 싶지 않습니다. 'AI'로 뭐든지 바로바로 척척척 알려주면 좋겠습니다.
방법 3. 데이터 과학자의 접근
사실 저런 중형 서버를 좀 굴려본 경험이 있으면 트래픽에 서버가 어떻게 반응할지에 대해서 개략적인 지식이 이미 있습니다. 굳이 비싼 서버를 살 필요도 없고, 홈 서버 수준의 작은 서버에서 셋팅을 다 한 다음에 AWS에서 인스턴스들만 몇 개 띄워 5분 남짓만 가상의 Live 서버를 돌려보면 필요한 데이터를 다 얻을 수 있습니다.
그 데이터를 바탕으로 시뮬레이션 모델을 만들어야죠.
IT시스템을 잘 모르기는 하지만 CEO도 나름대로 온갖 종류의 비용 절감 아이디어가 있고, 회사의 여러 직군이 회의를 하다보면 위에 예시를 들었던 프론트 엔드 개발팀과 마케팅 팀 간의 논쟁처럼, 회사 사정상 가능한 아이디어가 있고, 불가능한 아이디어가 있습니다. 여러 아이디어가 조합이 될 수도 있습니다.
위의 5분 동안 다양한 조합의 데이터를 뽑아놓으면, 1시간 남짓도 안 들여서 뚝딱 시뮬레이션 시스템을 만들 수 있습니다. 다양한 가능성에 대해 시뮬레이션을 돌려보면서 위의 회의를 좀 더 근거 있는 숫자를 놓고 이야기를 할 수 있겠죠.
뿐만 아니라, 시리즈B까지 투자하신 투자사들과 회사에 남은 Runway에 맞춰 광고비에 얼마를 배정할지, 서버 비용은 얼마가 드는지에 대해서 이야기할 때도 쓸 수 있고, 신규 시리즈 C 투자사 입장에서
이 회사는 AI/Data Science 역량을 제대로 확보하고 있구나
라는 신호를 줄 수도 있습니다.
더 자세한 예시들은 시험 문제 해설 수준이 되어버리니 위의 SIAI 기출문제 해설을 참고하시기 바랍니다.
수학을 언어처럼 써야 한다며?
위에서는 단순히 예시만 들어놨습니다만, 가끔은 5분 실험에 없었던 가능성이 회의 중에 대두될수도 있고, 거기에 맞춰 기존 데이터들을 일부 보정해야 할 수도 있습니다.
경쟁사가 이벤트를 했던 날은 트래픽이 확 줄어들었을테니, 그런 데이터를 써야 할 때는 사정에 맞춰 어떨 때는 도구변수(Instrumental variable)를 찾아서 유사성을 최대한 보존할 수도 있고, Sub-sampling 전략을 취할 수도 있습니다. 시간의 흐름을 추적해야 한다면 Kalman filter가 적절한 대응책일 수도 있고, 패턴의 복잡성을 잡아내는 걸로 RNN을 쓸려고 했더니 매주 목요일 이벤트 때 마다 데이터가 '발산'하는 관계로 RNN을 그대로 쓸 수 없으니 데이터를 2개 이상의 그룹으로 구분하는 전략을 써야 할 수도 있습니다.
수 많은 가능성 중에 생각나는대로 잠깐 정리해 봤는데, 기업 별로 현실은 훨씬 더 복잡할 겁니다.
저런 상황들에 적절하게 대응할 수 있도록 학교에서 배운 수학을 조금씩 뜯어고치는 것이 바로 '수학을 언어처럼' 쓰는 겁니다. 저 짧은 문단에 언급된 지식은 어지간한 '머신러닝', '딥러닝' 수업을 들으면 다 알 수 있습니다. 상식이 됐다고 해도 과언이 아닙니다. 그런데, 주어진 데이터, 주어진 상황에 맞춰서 수학을 가져다 쓸 수 있어야 회사에 도움이 됩니다. 저는 이걸 DGP (Data-Generating Process)에 따라 모델을 만들어야 된다고 표현합니다.
영어 단어를 60,000개 암기 했다고 영어를 잘하는 것이 아니라, 그 단어들을 자유자재로 엮어서 지식을 전달할 수 있어야 영어를 잘 하는 것 아닌가요? (혀만 잘 굴러가면 영어를 잘 하는건가요? ㅋㅋ)
제대로 데이터 과학 훈련이 되지 않은 2류 인재를 쓰고 있거나, 아예 개발자 중에 'AI전용 Library'를 몇 개 불러와서 쓸 줄 안다는 이유로 '데이터 전문가'라고 타이틀을 붙여놓은 경우에는 어떤 사건이 벌어질까요?
아마 '통밥'으로 '때리고' 있을 겁니다.
트래픽 예측을 해 준다는 AWS, Azure의 시스템을 쓰면, Google Analytics를 쓰면 좀 더 정확해질까요?
한국 기업들에서 '데이터 전문가'를 만났을 때 위와 같은 사고 구조를 갖추고 모델을 변형하는 능력을 갖춘 분을 만난 적도 거의 없었고, 만난다고 해도 수학으로 모델을 만드는 훈련을 받은 제 입장에서는 너무 조잡해 보였습니다. 이게 한국 기업 인력들의 현실이더군요.
'AI/Data Science 연구 이야기'는 그런 시뮬레이션을 '사고 실험' 형식으로 풀어내는 예시들을 몇 개 갖고 와 봤습니다.
모쪼록 눈이 뜨인 분들이 본인의 부족함을 깨닫고, 데이터 과학을 실생활에 응용하는 것이 어떤 것인지에 대한 인식이 잡히는데 도움이 되기를 바랍니다.
Picture
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.