Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Input
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Input
본 문서는 GIAI 산하에서 운영되는 스위스AI대학(Swiss Institute of Artificial Intelligence, SIAI)의 강의노트 중 일부를 한국어로 번역한 것입니다.
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Published
Modified
People following AI hype are mostly completely misinformed AI/Data Science is still limited to statistical methods Hype can only attract ignorance
As a professor of AI/Data Science, I from time to time receive emails from a bunch of hyped followers claiming what they call 'recent AI' can solve things that I have been pessimistic. They usually think 'recent AI' is close to 'Artificial General Intelligence', which means the program learns by itself and it is beyond human intelligence level.
No doubt that many current AI tools are far more advanced than medieval 'machines' that were discussed in the Scientific American article, but human generated AI tools are still limited to pattern finding and abstracting it by featuring common parts. The process requires to implement a logic, be it human found or human's programmed code found, and unfortunately the machine codes that we rely on is still limited to statistical approaches.
AI hype followers claim that recent AI tools have already overcome needs for human intervention. The truth is, even Amazon's AI checkout that they claimed no human casher is needed is founded to be under large number of human inspectors, according to the aforementioned Scientific American article.
As far as I know, 9 out 10, in fact 99 out of 100 research papers in second tier (or below) AI academic journals are full of re-generation of a few leading papers on different data sets with only a minor change.
The leading papers in AI, like all other fields, change computational methodologies for a fit to new set of data and different purposes, but the technique is unique and it helps a lot of unsolved issues. Going down to second tier or below, it is just a regeneration, so top class researchers usually don't waste time on them. The problem is that even the top journals are not open only for ground breaking papers. There are not that many ground breaking papers, by definition. We mostly just go up one by one, which is already ultra painful.
Going back to my graduate studies, I tried to establish a model for high speed of information flow among financial investors that leads them to follow each other and copy the winning model, which results in financial market overshooting (both hype/crash) at an accelerated speed. The process of information sharing that results in suboptimal market equilibrium is called 'Hirshleifer effect'. Modeling that idea into an equation that fits to a variety of cases is a demanding task. Every researcher has one's own opinion, because they need to solve different problems and they have different backgrounds. Unlikely we will end up with one common form for the effect. This is how the science field works.
Hype that attracts ignorance
People outside of research, people in marketing to raise AI hype, and people unable to understand researches but can understand marketers' catchphrases are those people who frustrate us. As mentioned earlier, I did try to persuade them that it is only a hype and the reality is far from the catch lines. I have given up doing so for many years.
Friends of mine who have not pursued grad school sometimes claim that they just need to test the AI model. For example, if an AI engineer claims that his/her AI can win against wall street's top-class fund managers by double to tripple margin, my friends think all they need as a venture capitalist is to test it for a certain period of time.
The AI engineer may not be smart enough to show you failed result. But a series of failed funding attempts will make him smarter. From a certain point, I am sure the AI engineer begins showing off successful test cases only, from the limited time span. My VC friends will likely be fooled, because there is not such an algorithm that can win against market consistently. If I had that model, I would not go for VC funding. I would set up a hedge-fund or I will just trade with my own money. If I know that I can win with 100% probability and zero risk, why share profit with somebody else?
The hype disappears not by a few failed tests, but by no budget in marketing
Since many ignorant VCs are fooled, the hype continues. Once the funding is secured, the AI engineer runs more marketing tools to show off so that potential investors are brain-washed by the artificial success story.
As the test failed multiple times, the actual investments with fund buyers' money also fails. Clients begin complaining, but the hype is still high and the VC's funding is not dry yet. In addition to that, now the VC is desperate to raise the invested AI start-up's value. He/She also lies. The VC maybe uninformed of the failed tests, but it is unlikely that he/she hears complains from angry clients. The VC's lies, however unintentional, support the hype. The hype goes on. Until when?
The hype becomes invisible when people stop talking about. When people stop talk about it? If the product is not new anymore? Well, maybe. But for AI products, if it has no real use cases, then people finally understand that it was all marketing hype. The less clients, and the less words of mouth. To pump up dying hype, the company may put in more budget to marketing. They do so, until it completely runs out of cash. At some point, there is no ad, so people just move onto something else. Finally, the hype is gone.
Then, AI hype followers no longer send me emails with disgusting and silly criticism.
Following AI hype vs. Studying AI/Data Science
On the contrary, there are some people determined to study this subject in-depth. They soon realize that copying a few lines of program codes on Github.com does not make them experts. They may read a few 'tech blogs' and textbooks, but the smarter they are, the faster they catch that it requires loads of mathematics, statistics, and hell more scientific backgrounds that they have not studied from college.
They begin looking for education programs. For the last 7~8 years, a growing number of universities have created AI/Data Science programs. At the very beginning, many programs were focused too much on computer programming, but by the competition of coding boot-camps and accreditational institutions' drive, most AI/Data Science programs in US top research schools (or similar level schools in the world) offer mathematically heavy courses.
Unfortunately, many students fail, because math and stat required to professional data scientists is not just copying a few lines of program codes from Github.com. My institution, for example, runs Bachelor level courses for AI MBA and MSc AI/Data Science for more qualified students. Most students know the MSc is superior to AI MBA, but only few can survice. They can't even understand AI MBA's courses that are par to undergrad. Considering US top schools' failing rates in STEM majors, I don't think it is a surprise.
Those failing students are still better than AI hype followers, so highly unlikely be fooled like my ignorant VC friends, but they are unfortunately not good enough to earn a demaing STEM degree. I am sorry to see them walk away from the school without a degree, but the school is not a diploma mill.
The distance from AI hype to professional data scientists
Graduated students with a shining transcript and a quality dissertation find decent data scientist positions. Gives me a big smile. But then, in the job, sadly most of their clients are mere AI hype followers. Whenever I attend alum gathering, I get to hear tons of complaints from students about the work environment.
It sounds like a Janus-face case to me. On the one side, the company officials hires data scientists because they follow AI hype. They just don't know how to make AI products. They want to make the same or the better AI products than competitors. The AI hype followers with money create this data scientist job market. On the other side, unfortunately the employers are even worse than failing students. They hear all kinds of AI hype, and they just believe all of them. Likely, the orders given by the employers will be far from realistic.
Had the employers had the same level knowledge in data science as me, would they have hired a team of data scientists for products that cannot be engineered? Had they known that there is no AI algorithm that can consistently win against financial markets, would they have invested to the AI engineer's financial start-up?
I admit that there are thousands of unsung heros in this field without much consideration from the market due to the fact that they have never jumped into this hype marketing. The capacity of those teams must be the same as or even better than world class top-notch researchers. But even with them, there are things that can be done and cannot be done by AI/Data Science.
Hype can only attract ignorance.
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Don't be (extra) afraid of math. It is just a language
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Published
Modified
Math in AI/Data Science is not really math, but a shortened version of English paragraph. In science, researchers often ask 'plz speak in plain English', a presentation that math is just to explain science in more scientific way.
I liked math until high school, but it became an abomination during my college days. I had no choice but to make records of math courses on my transcript as it was one of the key factors for PhD admission, but even after years of graduate study and research, I still don't think I like math. I liked it when it was solving a riddle.
The questions in high school textbooks and exams are mostly about finding out who did what. But the very first math course in college forces you to prove a theorem, like 0+0=0. Wait, 0+0=0? Isn't it obvious? Why do you need a proof for this? I just didn't eat any apple, so did my sister. So, nobody ate any apple. Why do you need lines of mathematical proof for this simple concept?
Then, while teaching AI/Data Science, I often claim that math equations in the textbook are just short version of long but plain English. I tell them "Don't be afraid of math. It is just a language." Students are usually puzzled, and given a bunch of 0+0=0 like proof in the basic math textbooks for first year college courses, I get to grasp why my students showed no consent to the statement (initially). So, let me illustrate my detailed back-up.
Source=Pexel
Math is just a language, but only in a certain context
Before I begin arguing math is a language, I would like to make a clear statement that math is not really a language as in academic defintion of language. The structure of math theorem and corollary, for example, is not a replacement of paragraph with a leading statement and supporting examples. There might be some similarity, given that both are used to build logical thinking, but again, I am not comparing math and language in 1-to-1 sense.
I still claim that math is a language, but in a certain context. My topic of study, along with many other closely related disciplines, usually create notes and papers with math jargons. Mathematicians maybe baffled by me claiming that data science relies on math jargons, but almost all STEM majors have stacks of textbooks mostly covered with math equations. The difference between math and non-math STEM majors is that the math equations in non-math textbooks have different meaning. For data science, if you find y=f(a,b,c), it means a, b, and c are the explanatory variables to y by a non-linear regressional form of f. In math, I guess you just read it "y is a function of a, b, and c."
My data science lecture notes usually are 10-15 pages for a 3-hour-long class. It might look too short for many of you, but in fact I need more time to cover the 15-pager notes. Why? For each page, I condense many key concepts in a few math equations. Just like above statement "a, b, and c are the explanatory variables to y by a non-linear regressional form of f", I read the equations in 'plain English'. In addition to that, I give lots of real life examples of the equation so that students can fully understand what it really means. Small variations of the equations also need hours to explain.
Let me bring up one example. Adam, Bailey, and Charlie have worked together to do a group assignment, but it is unsure if they split the job equally. Say, you know exactly how the work was divided. How can you shorten the long paragraph?
y=f(a,b,c) has all that is needed. Depending on how they divided the work, the function f is determined. If y is not a 0~100 scale grade but a 0/1 grade, then the function f has to reflect the transformation. In machine learning (or any similar computational statistics), we require logistic/probit regressions.
In their assignment, I usually skip math equation and give a long story about Adam, Bailey, and Charlie. As an example, Charlie said he's going to put together Adam's and Bailey's research at night, because he's got a date with his girlfriend in the afternoon. At 11pm, while Charlie was combining Adam's and Bailey's works, he found that Bailey almost did nothing. He had to do it by himself until 3am, and re-structured everything until 6am. We all know that Charlie did a lot more work than Bailey. Then, let's build it in a formal fashion, like we scientists do. How much weight would you give it to b and c, compared to a? How would you change the functional form, if Dana, Charlie's girlfriend, helped his assignment at night? What if she takes the same class by another teacher and she has already done the same assignment with her classmates?
If one knows all possibilities, y=f(a,b,c) is a simple and short replacement of above 4 paragraphes, or even more variations to come. This is why I call math is just a language. I am just a lazy guy looking for the most efficient way of delivering my message, so I strictly prefer to type y=f(a,b,c) instead of 4 paragraphes.
Math is a univeral language, again only in a certain context
Teaching data science is fun, because it is like my high school math. Instead of constructing boring proof for seemingly an obvious theorem, I try to see hidden structures of data set and re-design model according to the given problem. The diversion from real math is due to the fact that I use math as a tool, not as a mean. For mathematicians, my way of using math might be an insult, but I often say to my students that we do not major math but data science.
Let's think about medieval European countries when French, German, and Italian were first formed by the process of pidgin and creole. In case you are not familiar with two words, pidgin language is to refer a language spoken by a children by parents without common tongue. Creole language is to refer a common language shared by those children. When parents do not share common tongue, children often learn only part of the two languages and the family creates some sort of a new language for internal communication. This is called pidgin process. If it is shared by a town or a group of towns, and become another language with its own grammar, then it is called creole process.
For data scientists, mathematics is not Latin, but French, German, or Italian, at best. The form is math (like Latin alphabet), but the way we use it is quite different from mathematicians. For major European languages, for some parts, they are almost identical. For data science, computer science, natural science, and even economics, some math forms mean exactly the same. But the way scientists use the math equations in their context is often different from others, just like French is a significant diversion from German (or vice versa).
Well-educated intellectuals in medieval Europe should be able to understand Latin, which must have helped him/her to travel across western Europe without much trouble in communication. At least basic communication would have been possible. STEM students with heavy graduate course training should be able to understand math jargons, which help them to understand other majors' research, at least partially.
Latin was a universal language in medieval Europe, so as math to many science disciplines.
Math in AI/Data Science is just another language spoken only by data scientists
Having said all that, I hope you can now understand that my math is different from mathematician's math. Their math is like Latin spoken by ancient Rome. My math is simply Latin alphabet to write French, German, Italian, and/or English. I just borrowed the alphabet system for my own study.
When we have trouble understanding presentations with heavy math, we often ask the presentor, "Hey, can you please lay it out in plain English?"
The concepts in AI/Data Science can be, and should be able to be, written in plain English. But then 4 paragraphes may not be enough to replace y=f(a,b,c). If you need way more than 4 paragraphes, then what's the more efficient way to deliver your message? This is where you need to create your own language, like creole process. The same process occurs to many other STEM majors. For one, even economics had decades of battle between sociology-based and math-based research methods. In 1980s, sociology line lost the battle, because it was not sharp enough to build the scientific logic. In other words, math jargons were a superior means of communication to 4 paragraphes of plain English in scientific studies of economics. Now one can find sociology style economics only in a few British universities. In other schools, those researchers can find teaching positions in history or sociology major. And, mainstream economists do not see them economists.
The field of AI/Data Science evolves in a similar fashion. For once, people thought software engineers are data scientists in that both jobs require computer programming. I guess now in these days nobody would argue like that. Software engineers are just engineers with programming skills for websites, databases, and hardware monitoring systems. Data Scientists do create computer programs, but it is not about websites or databases. It is about finding hidden patterns in data, building a mathematically robust model with explanatory variables, and predicting user behaviors by model-based pattern analysis.
What's still funny is that when I speak to another data scientists, I expect them to understand y=f(a,b,c), like "Hey, y is a function of a, b, and c". I don't want to lay it out with 4 paragraphes. It's not me alone that many data scientists are just as lazy as I am, and we want our counterparties to understand the shorter version. It may sound snobbish that we build a wall against non-math speakers (depsite the fact that we also are not math majors), but I think this is an evident example that data scientists use math as a form of (creole) language. We just want the same language to be spoken among us, just like Japanese speaking tourists looking for Japanese speaking guide. English speaking guides have little to no value to them.
Math in AI/Data Science can be, should be, and must be translated to 'plain English'
A few years ago, I have created an MBA program for AI/Data Science that shares the same math-based courses with senior year BSc AI/Data Science, but does not require hard math/stat knoweldge. I only ask them to borrow the concept from math heavy lecture notes and apply it to real life examples. It is because I wholeheartedly believe that the simple equation still can be translated to 4 paragraphes. Given that we still have to speak to each other in our own tongue, it should be and must be translated to plain language, if to be used in real life.
As an example, in the course, I teach cases of endogeneity, including measurement error, omitted variable bias, and simultaneity. For BSc students, I make them to derive mathematical forms of bias, but for MBA students, I only ask them to follow the logic that what bias is expected for each endogenous case, and what are closely related life examples in business.
An MBA student tries to explain his company's manufacture line's random error that slows down automated process by measurement error. The error results in attenuation bias that under-estimates mismeasured variable's impact in scale. Had the product line manager knew the link between measurement error and attenuation bias, the loss of automation due to that error must have attracted a lot more attention.
Like an above example, some MBA students in fact show way better performance than students in MSc in AI/Data Science, more heavily mathematical track. They think math track is superior, although many of them cannot match math forms to actual AI/Data Science concepts. They fail not because they do not have pre-training in math, but because they just cannot read f(a,b,c) as work allocation model by Adam, Bailey, and Charlie. They are simply too distracted to math forms.
During admission, there are a bunch of stubborn students with a die-hard claim that MSc or death, and absolutely no MBA. They see MBA a sort of blasphamy. But within a few weeks of study, they begin to understand that hard math is not needed unless they want to write cutting edge scientific dissertations. Most students are looking for industry jobs, and the MBA with lots of data scientific intuition was way more than enough.
The teaching medium, again, is 'plain English'.
With the help of AI translator algorithms, I now can say that the teaching medium is 'plain language'.
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Published
Modified
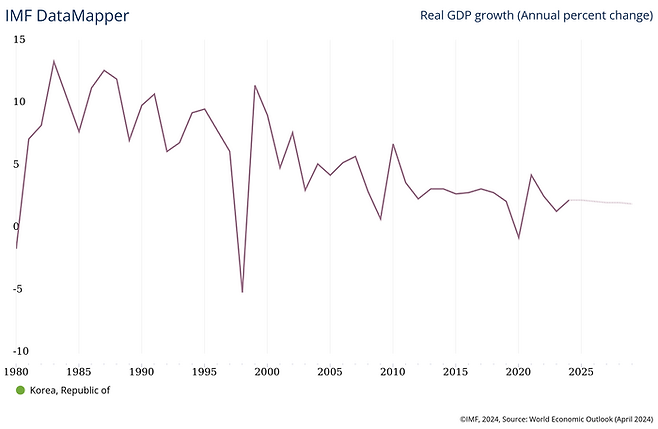
Korean GDP growth was 6.4%/y for 50 years until 2022, but down to 2.1%/y in 2020s. Due to low birthrate down to 0.7, population is expected to 1/2 in 30 years. Policy fails due to nationwide preference to leftwing agenda. Few globally competent companies leave the country.
Financial Times, on Apr 22, 2024, reported that South Korean economic miracle is about to be over. The claim is simple. The 50 years of economic growth from 1970 to 2022 with 6.4%/year is replaced by mere 2.1%/year growth in 2020s, and it will be down to 0.6% in the 2030s and 0.1% in 2040s.
For a Korean descendent, it is no secret that the country's economy has never been active since 1997 when Asian financial crisis had a hard hit to all east Asian countries. Based on IMF's economic analysis, South Korea's national GDP had grown over 7% per year until 1997, and with linear projection, it was expected that South Korea will catch up western European major economies in early 2010s by per capita GNI. Even after the painful recovery until 2002, per year growth rate was over 5% for another a decade, way above pessimistic economists' expectation, whose projection was somewhere near Japan's 1990s, the country nearly stopped growing after the burst of property bubble at the end of 1980s.
IMF DataMapper Korea GDP Growth
The 1970s model worked until 1990s
South Korean economic growth is mostly based on 1970s model that the national government provided subsidy highly export driven heavy industires. The country provide upto 20% of national GDP as a form debt insurnace to Korean large manufacturers for their debt-financing from rich countries. The model worked well up until late 1980s. Economic prosperity by extremely favorable global economic conditions coined as '3-Lows (Low Korean won, Low Petro price, Low interest rate)'. The success helped the economy to rely on short-term borrowing from US, Japan, and other major economies until 1997.
Forced to fire-sale multiple businesses at a bargain price, the passion for growth in the country was gone. Large business owners become extremely conservative on new investments. They also turned heads to domestic market, where competitors are small and weak. SMEs have been wiped out by large conglomerates, most of which were incapable of competiting internationally, thus turning to safe domestic battle.
Had time and money, but collective policy failures killed all
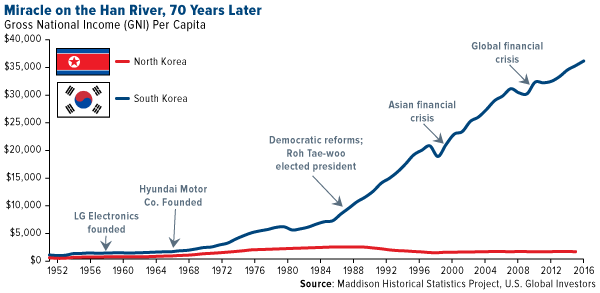
Compared to North Korean economic struggle, South Korea has been the symbol of success in capitalism. Over the 50 years, South Korean per capital GNI has grown from US$1,000 to US33,000, while Northern brothers are still struggling with US$1,000 to US$2,000, depending on agricultural production affected by weather conditions. In other words, while North Korea is still in pre-industrialization economy, the South has grown to a major industrial power with lots of cutting edge technological products, including semiconductors by Samsung Electrics and SK Hynix.
The country was able to keep higher than expected growth up until 2020, largely because of China's massive import. China, since the opening of its economy in 1998 by joing WTO(World Trade Organization). China has been the key buyer of South Korean electric appliances, smartphones, semiconductors, and many other tech products, most of which were crucial for its own economic developement.
But experts have raised attention that China's technological catch-up was a growingly imminent threat to Korean's tech superiority. The gap is now mostly gone. Even the US is now raising a bar high against China for 'security purpose'. The fact that the US has been keen on China's national challenge to semiconductor industry now even to chem and bio is an outstanding proof that China is no longer a tech follower to western key economic leaders, not to mention South Korea.
US-China trade war expedited Korea's fall
By a simple Cobb-Douglas model, with capital and labor, it is easy to guess that capital withdrawal from China resulted in massive surplus to the US market, where the economy is suffering from higher than usual inflation. It's the cost that the US market pays. On the other hand, without capital base, the Chinese economy is going to suffer from capital shock like Asian Financial Crisis of 1997. Facilities are there, but money is gone. Until there is any capital influx to fill the gap, be it by IMF and World Bank like 1997 or long-term internal capital building like Great Britain from 1970s to 2000s, we won't be seeing China's economic rise.
The sluggish Chinese economy deadly affected its neighbors. One of the trading partners that were hit hard is South Korea in Asia, Germany in Europe, and Apple in BigTechs. Germany used to be the symbol of economic growth in Europe, at least during European sovereign debt crisis of 2008-2012. Unlike other big tech companies, Apple kept its dependency to China until very recently. The company lost stock values by 40% since the peak in 2022. South Korean story is not that different. The major trading partner zipped its wallet. 15% to 40% of trade surplus, depending on industries, were disappeared. Korean companies were not ready to replace the loss by other sources.
The evident example that South Korea was not ready to China's withdrawal is its dependency to Aqueous urea solution(AUS) for diesel powered trucks. Over 90%, sometimes upto 100%, of AUS consumption in the nation was from Chinese sources, which was stopped twice recently. In Dec 2021 and Sep 2023, lack of AUS pushed Korea's large cargo freight trucks being inoperable. The country's logistic system was nearly shut down. The government tried to replace it for two years from 2021 to 2023, but the country still failed to avoid another AUS crisis in Sep 2023.
For South Korea, China was a mixed blessing. Dependency to China from 1998 upto 2020 helped the economy to keep high enough growth rate to run the country. But heavy dependency now creates detrimental effects to every corner of the country's industrial base. Simply put, Korea has been too dependent to China.
Education, policy, companies, all failed jointly and simultaneously
Fellow professors in major Korean universities do not expect Korea to rebound anytime soon. The economic growth model that worked in 1970s have not been working as early as late 1990s. The government officials have, however, been ignorant of failing system. Back then, under military regime, only successful business men were given government subsidy. The selection process was tough. Failing businesses were forced to close down, before creating any harm to wider economy.
But the introduction of democratic system that brough freedom to business, press, and civil rights groups deprived the government of total control on resource allocation. The country no longer is operated by a single powerful and efficient planner. While recovering from devastating financial crisis in 1997, every agents in the economy learned that the government is no longer a powerful fatherhood and tasted some economic freedom.
Had the freedom been regulated properly, the economy would have been armed by national support in subsidy, human resources, as well as 50 million domestic customer base. Instead, except a few internationally qualified products, most of them turned their heads inward. For lack of English speaking manpower, companies were not able to compete internationally, unless they have hard and unique products. Building a brand from 'copying machine' to 'tech leader' costs years of endeavor that we can only see successes in RAM chips and K-pop singers.
Korea had time to renew its economic policy. But Chinese honeyspot provided too much illusion that Korean companies thought its superiority will stay forever. Koreans have kept its 'copying machine' policy. The government officials were not as keen as 1970s, thus any sugarcoated success in overseas countries helped Korean companies to be in a position of demand to subsidy. The country stopped grow technologically. Industries, academia, and press become entangled to one goal. Massive exaggeration to earn government subsidy. For one, Korean government wasted US$10 billion just for basic programming courses in K-12 that are no longer needed in the era of Generatvie AI. In the meantime, China was not willing to stay culturally, technologically, and intellectually behind its tiny neighbor that they have looked down for the last two millenia.
While Korean education puts less and less emphasis on math/stat/science, Chinese took opposite steps. Now Korea's the most demanded college major is medical doctoral track, while Chinese put Mathematics as the top major. Despite higher competition to medical track with large expected income, some students no longer pursue medical track just because they are afraid of high school mathematics and science.
Aging society with lowest birthrate in the world
Will there be any hope in Korea? Many of us see otherwise. The country is dying, literally. The median age of the country is 49.5 as of year 2024. Generations born in 1980s had nearly 1 million babies in a year, while in 2020s they only have 200,000. The population, particularly in working age, will be shrunken to 1/5 in a few decades later. Due to touch economic conditions, young couples push marriage as late as 30s and 40s. Babies by women after 35 have shown some level of genetic defect that even 1/5 of working population won't be as effective as today.
Together with mis-guided educational policy, the country is expected to have less capable brain as the time goes. International competition will become more severe due to desperate Chinese catch up in technology. Companies have already lost passion for growth.
Economic reforms have been tried, but the unpopular minority seldom wins in elections. Even if it wins, the opposition is too strong to overcome. Officials expect that the country is on a ticking bomb without any immediate means of defusion.
Though I admit that other major economies are suffering from similar growth fatigue, it is at least evident that South Korea is now on the list of 'no-hope'. If you are looking for growth stocks, go and look for other countries.
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Why was 'Tensorflow' a revolution, and why are we so desperate to faster AI chips?
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Published
Modified
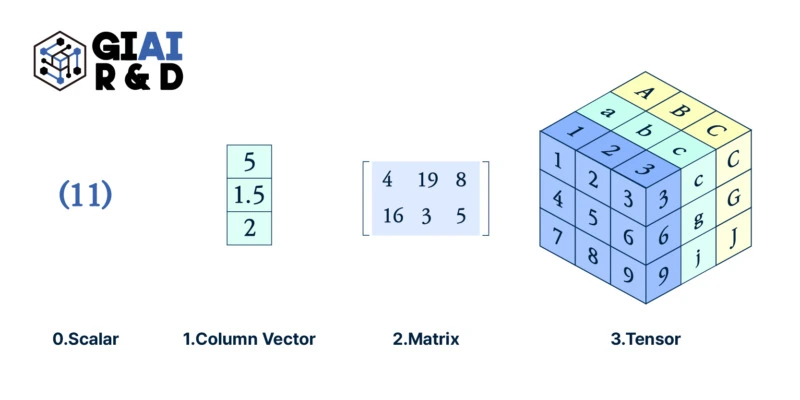
Transition from column to matrix, matrix to tensor as a baseline of data feeding changed the scope of data science, but faster results in 'better', only when we apply the tool to the right place, with right approach.
Back in early 2000s, when I first learned Matlab to solve basic regression problems, I was told Matlab is the better programming tool because it runs data by 'Matrix'. Instead of other software packages that feed data to computer system by 'column', Matlab loads data with larger chunk at once, which accelerates processing speed by O(nxk) to O(n). More precisely, given how the RAM is fed by the softwares, it was essentially O(k) to O(1).
Together with a couple of other features, such as quick conversion of Matlab code to C code, Matlab earned huge popularity. A single copy was well over US$10,000, but companies with deep R&D and universities with significant STEM research facilities all jumped to Matlab. While it seemed there were no other competitors, there was a rising free alternative, called R, that had packages handling data just like Matlab. R also created its own data handler, which worked faster than Matlab for loop calculation. What I often call R-style (like Gangnam style), replaced loop calculations from feeding column to matrix type single process.
R, now called Posit, became my main software tool for research, until I found it's failure to handling imaginary numbers. I had trouble reconciliating R's outcome with my hand-driven solution and Matlab's. Later, I ended up with Mathematica, but given the price tag attached to Mathematica, I still relied on R for communicating with research colleagues. Even after prevailing Python data packages, upto Tensorflow and PyTorch, I did not really bother to code in Python. Tensorflow was (and is) also available on R, and there was not that much speed improvement in Python. If I wanted faster calculation for multi-dimensional tasks that require Tensorflow, I coded the work in Matlab, and transformed to C. There initially was a little bug, but the Matlab's price tag did worth the money.
A few years back, I found Julia, which has similar grammar with R and Python, but with C-like speed in calculations with support for numerous Python packages. Though I am not an expert, but I feel more conversant with Julia than I do to Python.
When I pull this story, I get questions like wy I traveled around multiple software tools? Have my math models become far more evolved that I required other tools? In fact, my math models are usually simple. At least to me. Then, why from Matlab to R, Mathematica, Python, and Julia?
Since I only had programming experience from Q-Basic, before Matlab, I really did not appreciate the speed enhancement by 'Matrix'-based calculations. But when I switched to R, for loops, I almost cried. It almost felt like Santa's Christmas package had a console gamer that can play games that I have dreamed of for years. I was able to solve numerous problems that I had not been able to, and the way I code solution also got affected.
The same transition affected me when I first came across 'Tensorflow'. I am not a computer scientist, so I do not touch image, text, or any other low-noise data, so the introduction of tensorflow by computer guys failed to earn my initial attention. However, on my way back, I came to think of the transition from Matlab to R, and similar challenges that I had had trouble with. There were a number of 3D data sets that I had to re-array them with matrix. There were infinitely many data sets in shape of panel data and multi-sourced time series.
When in search for right stat library that can help solving my math problems in simple functions, R usually was not my first choice. It was mathematica, and it still is, but since the introduction of tensorflow, I always think of how to leverage 3D data structure to minimize my coding work.
Once successful, it not only helps me to save time in coding, but it tremendously changes my 'waiting' time. During my PhD, for one night, the night before supposed meeting with my advisor, I found a small but super mega important error in my calculation. I was able to re-derive closed solutions, but I was absolutely sure that my laptop won't give me a full-set simulation by the next morning. I cheated with the simulation and created a fake graph. My advisor was a very nice guy to pinpoint something was wrong with my simluation within a few seconds. I confessed. I was too in a hurry, but I should've skipped that week's meeting. I remember it took me years to earn his confidence. With faster machine tools that are available these days, I don't think I should fake my simulation. I just need my brain to process faster, more accurately, and more honestly.
After the introduction of H100, many researchers in LLM feel less burden on handling massive size data. As AI chips getting faster, the size of data that we can handle at the given amount of time will be increasing with exponential capacity. It will certainly eliminate cases like my untruthful communication with the advisor, but I always ask myself, "Where do I need hundreds of H100?"
Though I do appreicate the benefits of faster computer processing and I do admit that the benefits of cheaper computational cost that opens opportunities that have not been explored, it still needs to answer 'where' and 'why' I need that.
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Input
온라인 학위 저평가 원인은 대학들이 오프라인보다 입학 난이도 및 교육 난이도를 가볍게 운영하기 때문
장기간 온라인 교육에 대한 평가 절하 인식이 퍼져 있어 편견 확대되는 효과도
난이도 높이면 결국 학생들의 기초 실력과 열정에 따라 성취도 구분되는 효과 나와
지난 코로나19 기간을 겪으며 한국 사회에서도 온라인 교육 과정에 대한 편견이 많이 사라지는 했지만, 여전히 온라인 교육은 오프라인 교육보다 품질이 낮다는 편견이 강하다. 실제로 교육을 해보면서 느끼는 거지만, 동영상 강의를 만드는 것과 현장에서 강의하는 것 간에 강의 내용 자체는 큰 차이가 없지만, 학생들과 의사소통에서 격차가 발생하고, 동영상을 매번 새로 만드는 것이 아니라면 과거 내용을 전달하게 되는 문제가 생길 수는 있는 것 같다.
반대로 강의 내용을 반복적으로 들을 수 있어 동영상이 있는 편이 훨씬 더 좋다는 반응도 자주 겪는다. 내가 하는 강의는 수학, 통계학 기반의 인공지능 강의이다보니, 수학 용어, 통계학 이론을 까먹거나 모르는 학생들이 동영상을 여러 차례 반복 재생하면서 관련 개념들을 교과서, 구글 검색 등을 통해 찾아보는 경우가 많다고 들었다. 온라인 교육의 수준이 더 낮을 것이라는 편견이 강하지만, 오히려 온라인이어서 반복 재생이 가능하다는 점 때문에 좀 더 자신있게 고급 개념을 수업 시간에 던질 수 있게 된 것은 장점이라고 봐야할 것 같다.
온라인 학위가 오프라인보다 수준이 떨어진다고 생각하는 이유?
그간 온라인으로 학위 과정을 운영하면서 왜 일반에 오프라인과 온라인 간의 격차에 대한 편견이 생겼을까를 고민해왔다. 최근까지 경험을 바탕으로 내린 결론은, 강의 내용은 같아도 운영 방식이 다르다는 것이다. 도대체 어떻게 다를까?
가장 큰 차이는 온라인 학위 과정을 운영하는 대학들이 오프라인과 달리 치열한 경쟁 체제를 구축하지 않고, 입학의 문을 열어놓은 경우가 많다는 것이다. 국내의 국립방송통신대학(이하 방송대학)의 경우, 입학 서류 상의 미비점이 아닌 이상 불합격하는 사례를 찾아보기는 쉽지 않을 것이다. 같은 상황은 해외의 다른 온라인 대학으로 가도 크게 다르지 않다. 온라인 교육은 학위 과정의 보조 과정, 필요한 학점을 채워주는 과정 정도의 인식이 있지, 전문 학위로 버거운 도전을 해야하는 과정이라는 인식이 잡힐만큼 고난이도 학위 과정을 운영하는 경우는 극히 드물다.
또 하나 차이점이 있다면, 교수와 학생 간의 교류, 학생들 간의 교류에서 큰 차이가 나타난다는 점이다. 런던, 보스턴 등의 해외 주요 도시에서 대학원 학위 과정을 밟으면서 현지 체류를 위해 많은 시간 비용을 써야했던 점은 단점으로 작용했지만, 학위 과정에서 함께 공부하는 학생들과의 유대감, 친밀감은 굉장히 밀도 있게 쌓였다. 그런 친밀감이 단순히 얼굴을 알고, SNS 계정에서 '친구 맺기(Friend)'를 하는 것을 넘어, 학위 중 시험 문제, 어려운 내용들을 함께 공유하고, 논문을 쓰면서 답답한 내용들을 풀어나가는 공통된 경험을 했던 것이 있었기 때문에 오프라인에서의 교육이 좀 더 값진 교육이라고 생각하게 되었을 것이다.
국내의 방송대학, 해외의 주요 온라인 대학들도 학생들간 유대감, 친밀감 문제를 풀어내기 위해 시험을 온라인 대신 현장에서 치른다던가, 학생들 간의 스터디 그룹을 주선한다던가 하는 방식으로 학생 간의 공통된 접점을 만들어내기 위해 많은 노력을 한다.
이런 사례들을 보며 내가 내린 최종 결론은 결국 입학의 난이도, 학습 내용의 난이도, 학습 진도를 따라가기 위한 노력, 그리고 재학생들 사이에 유사한 눈높이 등이 그간 온라인 대학에서 찾아볼 수 없었기 때문에 우리가 오프라인과 온라인을 구분했었지 않냐는 결론을 얻게 됐다.
온라인 학위의 부족분을 메워넣으면 달라질 수 있을까?
우선 나는 교육 수준을 국내 대학에서는 볼 수 없는 수준으로 높였다. 강의 내용도 대부분 글로벌 명문 대학에서 내가 들었던 내용, 주변 친구들이 들었던 내용들을 바탕으로 구성했고, 시험문제도 글로벌 명문 대학 학생들도 만만치 않다고 느낄만한 수준으로 끌어올렸다. 국내의 명문 대학 학생들, 국내 대학 석·박사 학위자들이 온라인 대학이라는 이유로 가벼운 학위라고 생각했다가 화들짝 놀라 도망가는 경우도 많았고, 해외에 시험 문제가 공개되고 난 다음에도 대학 랭킹이 얼마나 높길래 이렇게 고급 문제를 출제하냐는 커뮤니티 게시글이 난 적도 있다. 온라인으로 운영되는 대학이라는 사실이 알려지고 나니 영어권 커뮤니티에서도 적잖은 파장이 일기도 했다.
확실히 교육 난이도를 끌어올리면 온라인이라고 가볍게 생각하는 부분이 크게 사라진다는 것을 깨닫는 경험을 얻었는데, 그럼 학생들의 성취도 측면에서 온라인과 오프라인은 확연한 차이가 날 수 있을까?
위의 표는 온라인으로 수업을 들은 학생들과 오프라인으로 수업을 들은 학생들 간의 시험 점수 격차가 유의미한지를 판단하기 위한 연구 결과의 일부를 발췌한 것이다. 우리 학교의 경우에는 오프라인 강의를 운영한 적은 없지만 오프라인으로 자주 방문해서 질문을 많이 한 학생과 아닌 학생들 간의 학점 차이에서 유사한 결론이 도출된 바 있다.
우선 위의 (1) - OLS 분석에서 온라인으로 수업을 들은 학생들이 오프라인으로 수업을 들은 학생들보다 약 4.91점 정도 부족한 성적을 받았다는 것을 확인할 수 있다. 학생의 수준이 다를 수도 있고, 공부를 열심히 안 했을 수도 있고 등등으로 다양한 조건들을 고려해야 하는데, 전혀 고려하지 않은 단순 분석이기 때문에 정확도는 매우 떨어진다. 실제로 온라인으로만 수업을 듣는 학생들이 게으름에 학교를 찾아가지 않는 스타일인 경우, 학습 열정이 부족한 것이 그대로 시험 점수로 반영될 수도 있지만, 합리적으로 반영되지 못한 분석 값이다.
이 문제를 해결하기 위해 (2) - IV에서는 학생들의 게으름이라는 외부 요소를 제거할 수 있는 도구변수(Instrumental Variable)로 오프라인 교실과 학생들의 거주지 간 거리를 활용했다. 거리가 가까울 수록 오프라인 수업을 들으러가기 쉬울 것이기 때문이다. 해당 변수를 이용해 외부 요소를 제거했음에도 불구하고 여전히 온라인 수강생들의 시험 점수가 2.08점 낮았다. 이걸 보고나면 온라인 교육이 학생들의 학업 성취도를 낮추는구나는 결론을 내릴 수 있게 된다.
그런데, 단순한 거리를 넘어, 학생들의 공부 열정을 활용할 수는 없을까는 의문이 생기더라. 여러 변수를 찾던 중에, 도서관 방문 숫자라는 데이터를 이용하면, 열정 있는 학생들이 좀 더 적극적으로 도서관을 찾을 것이라는 예상이 되는만큼 열정에 대한 적절한 지표로 활용할 수 있겠다는 생각이 들었다. 그렇게 (3) - IV로 변형된 계산을 해 보니, 도서관에 열심히 다니는 학생이 0.91점 더 높은 점수를 받았고, 온라인 교육으로 인한 점수 하락 폭은 불과 0.56점으로 줄어들었다.
여기서 또 한 가지 의문이 드는 부분은, 도서관이 학생들의 주거지와 얼마나 가까우냐는 것이다. 오프라인 교실이 가까운 것을 주요한 변수로 활용했던 것과 마찬가지로, 도서관이 얼마나 가까우냐도 분명히 도서관 방문 횟수에 영향을 주었을 확률이 높기 때문이다.
그래서 (4) - IV 계산을 이용해 기숙사를 무작위 추첨으로 배정받은 학생들이 교실과의 거리와 시험 점수 간 상관관계를 분석해 시험 점수에 직접적인 영향을 주지 않는다는 것을 확인한 후, 해당 그룹의 학생들 중 도서관 방문 빈도와 온라인 수강으로 인한 시험 점수 격차를 재계산했다.
(5) - IV에서 보듯이, 거리라는 변수가 완전히 제거된 상태에서 도서관 방문은 시험 점수 2.09점 상승에 도움을 줬고, 온라인 수강은 오히려 6.09점 상승에 보탬이 됐다.
위의 사례에서 볼 수 있듯이, (1)의 기초적인 단순 분석에서는 온라인 강의가 학생들의 학업 성취도를 떨어뜨린다는 오해 섞인 결론이 나오는 반면, 변수들 간의 문제를 재조정하고 난 (5) 계산에서는 거꾸로 온라인 강의를 열심히 듣는 학생들이 더 성취도가 높게 나왔다.
이는 실제 교육 경험과도 일치하는 것이, 동영상 강의를 1번만 듣는 것이 아니라 반복 수강을 하며 각종 자료를 계속 찾아보는 학생들일 수록 학업 성취도가 높다. 특히, 구간 반복, 중간 멈춤이 동영상 재생 중 수십차례 있었던 학생들이 빠르게 건너뛰기 위주로 강의를 시청한 학생들대비 20% 이상 성적이 좋았다. 학생들 중 스터디 그룹을 한 사례, 스터디 그룹 동료 학생들의 평균 점수, 점수 분산, 학위 과정 입학 전 기초 학력 상황 등의 변수 효과를 제거하는 작업을 거칠 경우, 동영상 강의 수강 패턴은 단순히 5점, 10점 수준의 격차가 아니라 합격, 불합격을 결정지을만큼 큰 차이를 나타냈다.
온라인이어서가 아니라 학생들의 태도와 학교의 운영 차이 때문
실제 데이터와 각종 연구를 바탕으로 자신있게 내릴 수 있는 결론은, 온라인 교육이 오프라인 교육에 비해서 저평가 받아야 할 플랫폼 상의 이유는 없다는 것이다. 차이가 발생하는 이유는 대학들이 온라인 교육 과정을 추가적인 돈벌이를 위한 평생교육원 방식으로 운영하고 있기 때문이고, 지난 수십년간 온라인 교육이 그렇게 가볍게 운영된 탓에 학생들이 편견을 가지고 접근하기 때문이었다.
실제로 고급 교육을 제공하고, 열정적으로 공부하지 않으면 낙오하는 것이 당연한 형태로 프로그램을 구성하자 오프라인과 차이가 크게 줄어들었고, 학생 본인의 열정이 학업 성취도를 결정하는 가장 중요한 요소로 대두됐다.
그럼에도 불구하고 완전한 비대면 교육은 교수와 학생, 학생들 간의 유대감 증가에 큰 도움이 되지 못하고, 학생들 개개인과 '눈 맞춤'을 못하는 만큼 교수 입장에서 학생들의 학업 성취도를 예상하는데 어려움을 준다. 특히 한국인 학생들의 경우는 질문을 하는 경우가 거의 없기 때문에, 질문마저 없는 경우에는 정말 학생들이 잘 따라오고 있는지 가늠하기 쉽지 않았던 경험이 있다.
보완 시스템으로는 주기적인 퀴즈, 과제 결과물에 대한 꼼꼼한 채점 등이 있을 것 같고, 온라인 강의가 라이브로 진행되고 있는 경우라면 학생들을 호명하며 질문을 던져보는 방식도 괜찮을 것 같다.
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Input
상권과 특정 세대 소비자 집중도 관계 분석시 동시성의 오류 발생할 가능성 높아
도구 변수를 이용해 둘 간의 복합 상관관계를 단순 상관관계로 분리해야
실제 기업 사례에서도 잘못된 계산 후 잘못된 결론 얻는 경우 많아
데이터 사이언스 관련 프로젝트를 하다보면, 비일비재하게 발생하는 사안이 인과관계 오류다. 원인이라고 생각했던 변수가 사실은 결과였고, 반대로 결과라고 생각했던 변수가 원인인 경우들이 상당히 많다. 이런 오류를 데이터 사이언스에서는 '동시성의 오류(Simultaneity)'라고 부른다. 관련 연구가 가장 먼저 시작된 곳은 경제학 중 계량경제학으로, 일반적으로 중요 데이터 상실(Omitted Variable), 데이터 부정확성(Measurement error)와 더불어 3대 데이터 내부 오류(Endogeneity error)로 불린다.
현실 사례로, 최근 우리 석사 학생의 졸업 논문을 하나 예시로 들어볼 수 있을 것 같다. 해당 학생은 홍대 앞 상권이 2030 청년을 불러모았을 것이라는 판단에 기초해, 2030 청년들이 모이는 주요 변수들을 찾고, 다른 변수들을 더 찾고나면 청년들이 모이는 상권을 구성하는 변수를 찾을 수 있지 않을까는 가정을 갖고 왔다. 학생의 가정이 합리적일 경우에는 향후 상권 분석을 하시는 분들이 쉽게 모델을 차용해서 쓸 수 있을 것이고, 상권분석이 단순히 작은 매장만 열려고 하는 분들 뿐만 아니라, 소비재 기업의 판촉 마케팅, 카드사의 길거리 마케팅 등등 다양한 분야에 응용될 수 있는 여지가 있다.
동시성의 오류(Simultaneity error)
그런데, 안타깝게도 홍대 앞 상권이 2030 청년을 불러모은 것이 아니라, 홍익대학교를 비롯한 인근 연세대학교, 이화여자대학교, 서강대학교 등의 학교 집단이 2030 청년을 불러모았고, 그 학생들이 움직이는 교통 요지 중 한 곳이 현재의 홍대 앞 상권이 되었다는 생각에 적절한 반박을 내놓지를 못하더라. 원인이라고 생각했던 홍대 앞 상권이 사실은 결과고, 결과라고 생각했던 2030 청년이 반대로 원인일 수 있는 것이다. 이런 동시성이 있는 경우에 무작정 회귀분석, 혹은 최근 인기를 얻고 있는 각종 비선형 회귀분석 모델(예. 딥러닝, 나무 모형 등등)을 이용할 경우, 원인-결과가 중첩되는 복합적인 인과관계 탓에 1개 변수의 효과를 과대/과소 계상하거나, 심하게는 해당 변수와 관련이 있는 모든 변수의 효과를 과대/과소 계상하는 오류를 범할 수 있다.
계량경제학계에서는 일찍부터 이런 경우를 해결하기 위해 '도구변수(Instrumental Variable)'이라는 개념을 갖고 왔다. 인과관계가 복합적으로 작용하는 부분을 비롯해 3대 데이터 내부 오류 상황 중 어떤 경우에 관계없이 문제가 생긴 부분을 제거해주는 데이터 전처리(Data pre-processing) 작업 중 하나라고 할 수 있다. 데이터 사이언스 분야가 최근에 생긴 이후 주변 학문들로부터 각종 방법론을 차용하는 중인데, 출발점이 경제학계다보니 아무래도 공학계열 출신 전공자들에게는 낯선 방법론이기도 하다.
특히 완벽한 정확성을 따지는 수학, 통계학 등의 자연과학 방법론으로 사고 방식이 정리된 분들께는 '가짜 변수(Fake variable)'이라는 지적을 받는 경우도 종종 있으나, 우리 현실의 데이터는 각종 오류와 상관관계를 갖고 있는만큼, 현실 데이터를 이용한 연구에서는 피할 수 없는 계산이다.
도구 변수를 찾아 데이터 전처리부터
다시 홍대 앞 상권으로 돌아와서, 연구 주제를 갖고 온 학생에게 둘 간의 복합적인 인과관계 중 한 개 변수와 직접적인 관련이 있지만 (Revelance condition) 다른 변수와는 큰 관련이 없는 변수(Orthogonality condition)을 찾을 수 있냐는 질문을 던져봤다. 홍대 앞 상권이 커지는데 영향을 주지만 2030 청년들이 모이는데는 직접적인 영향을 주지 않은 변수, 혹은 2030 청년들이 모이는데는 직접적인 영향을 주지만 홍대 앞 상권과는 직접적인 관련이 없는 변수를 찾으면 된다.
우선 주변의 대학들의 존재는 2030 청년들이 모이는데 결정적인 역할을 한다. 이 중 속칭 '인싸'인 학생들이 홍대 앞 상권 출입이 더 잦을 것이고, 반대로 '아싸'인 청년들은 홍대 앞 상권보다 다른 상권을 더 이용할 가능성이 높다. 이런 대학들의 존재가 2030 청년들의 군집에 더 도움이 되었는지, 그런데 홍대 앞 상권과 직접적인 관련이 없는지 가장 쉽게 알 수 있는 방법은 학교를 1개씩 제거해보면서 청년 밀집도를 보는 것인데, 안타깝게도 인근 4개 대학을 1개씩 분리하며 보기는 어렵다. 오히려 코로나19 기간 동안 비대면으로 공부하면서 학교 주변을 찾는 학생들이 급감한 상태에서 홍대 상권이 어떤 방식으로 작동했을지를 따지는 편이 더 합리적인 도구 변수 선정이 된다.
그 외에도 홍대 앞과 신촌 역 일대 비교를 통해 각각 교통의 요지, 높은 학생 군집도라는 공통점을 갖고 있음에도 불구하고 상권의 구성 요소에 해당하는 상점들의 특성들을 구분해보는 것도 좋은 방법이다. 일반적인 인식에 홍대 앞 상권은 다른 곳에서 볼 수 없는 독특한 상점들이 몰린 곳이라는 이미지가 있는만큼, 톡특한 상점의 숫자가 복합적인 인과관계를 분리하는 변수로 쓰일 수도 있다.
실제 계산이 진행되는 방식은?
그간 국내에서 가장 답답했던 부분은, 모든 변수를 다 집어넣고 '인공지능'이 알아서 답을 찾아준다는 맹신을 갖고 데이터를 모두 입력해보는 계산법들이었다. 그 중 여러 변수를 넣었다 뺐다만 반복하는 계산방법으로 '단계분석법(Stepwise regression)'이라는 것이 있는데, 통계학계에서도 이미 이용을 조심해야 된다는 경고가 있음에도 불구하고 제대로 통계학 교육을 받지 않은 다수의 공학도들이 아무런 생각없이 마구잡이로 해당 계산법을 이용하는 것을 너무 자주 봤다.
위에서 지적했듯이 복합적인 인과관계를 담고 있는 '동시성의 오류'를 제거하지 않은 상태에서 선형 혹은 비선형 계열의 회귀분석 계산을 할 경우, 변수들의 효과가 과대/과소 계상되는 사건이 나타날 수밖에 없는 만큼, 이런 경우에는 먼저 데이터 전처리 작업을 필수적으로 진행해야 한다.
도구변수를 쓰는 데이터 전처리 작업은 데이터 사이언스 분야에서 '2단계 회귀분석(2-Stage Least Square, 2SLS)'라고 부른다. 1단계에서 복합 인과관계를 제거해 단순 인과관계로 정리한 후, 2단계에서 우리가 알고 있는 일반적인 선형 혹은 비선형 회귀분석 작업을 진행하는 것이다.
1단계의 제거 작업은 위에서 선정된 도구변수 1개, 혹은 여러 개를 이용해 설명 변수로 쓰는 변수에 회귀분석 작업을 진행한다. 위의 홍대 앞 상권 사례로 돌아오면, 2030 청년들이 우리가 쓰고 싶은 설명 변수고, 2030 청년들과 관계가 있을 것 같지만 정작 홍대 앞 상권과는 직접 관련이 없을 것으로 예상되는 인근 대학교 관련 변수를 활용하는 것이다. 2030 청년들의 숫자와 대학교의 코로나19 팬데믹 기간 전후 관계를 0, 1로 구분해 회귀분석을 진행할 경우, 2030 청년 중 대학교로 인해 설명되는 부분만 추출해낼 수 있다. 이렇게 추출된 변수를 쓸 경우에는 위의 복합 인과관계가 아니라 단순 인과관계로 홍대 앞 상권과 2030 청년들 간의 관계를 파악할 수 있는 것이다.
실제 현장 기업의 실패 사례
실제 데이터가 없으니 함부로 단견을 짓기는 어렵지만, 그간 겪어본 '동시성의 오류' 사례를 봤을 때, 2SLS 작업 없이 단순히 모든 데이터를 집어넣고 선형 혹은 비선형 회귀분석 계산을 했을 경우, 2030 청년들이 많기 때문에 홍대 앞 상권이 확대되었다는 단순한 결론에 굉장히 많은 가중치가 쏠리고, 2030 청년 이외의 인근 주거 및 상업지역 월세, 독특한 상점의 유무, 지하철 및 버스 정류장 인근의 접근성 등은 크게 유의미하지 않은 값으로 나올 것이다. 둘 간의 복합 상호 작용이 다른 변수에 배정되었어야 할 설명력을 앗아갔기 때문이다.
국내에서 제대로 교육을 받지 못한 다수의 공학도들이 여러 변수를 교차로 집어넣는 '단계분석법' 관점의 나무 모형, 딥러닝 등에 의존해 '인공지능이 찾아준 결론'이라는 주장을 하는 경우도 있으나, 변수 간 설명 구조가 선형이냐 비선형이냐의 차이만 있을 뿐, 따라서 변수의 설명력 비중치가 일부 수정되는 차이만 있을 뿐, 결론이 엉망으로 나오는 것은 동일하다.
위의 사례는 실제로 모 카드 회사와 통신사가 공동으로 마포구 일대의 상권 분석을 했을 때 저질렀던 잘못과 완벽하게 일치한다. 해당 연구에 참여했던 관계자 분이 '2030 청년들 모으는게 답이더라구요'라는 표현을 쓰길래, 계산방법을 확인해봤고, 예상했던대로 '도구변수'를 활용해야한다는 이해도가 전혀 없었던 탓에 데이터 전처리를 단순히 결측값 버리는 작업 정도로만 생각했었다는 것을 알 수 있었다.
사실 홍대 뿐만 아니라 서울 지역 주요 상권을 구성하는 요소는 매우 복합적이다. 2030 청년들이 모이는 것은 대부분 복합적인 상권 구성 요소가 사람을 끌어들이는 매력이라는 결과값을 만들어냈기 때문인데, 위와 같은 단순 '인공지능 계산'으로 답을 찾아내기는 어렵다. 현재 시장에서 이뤄지고 있는 데이터 분석 작업의 오류를 지적하려다보니 단순히 '동시성의 오류'만을 선택했으나, 중요 변수를 놓쳐서 발생하는 오류(Omitted Variable Bias), 모아놓은 변수 데이터의 부정확성(Attenuation bias by measurement error) 등을 복합적으로 고려해야하는, 상당히 고급 모델링 작업이 필요하다.
잘못된 머신러닝, 딥러닝, 인공지능 교육을 받고 있는 학생들이 위의 개념을 익혀 합리적이고 체계적인 모델링을 할 수 있게 되기를 기대해본다.
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Input
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Neural Network 모델은 Borel-measurability가 충족되는 데이터에서만 쓸 수 있다
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.
Input
Neural Network 계산법이 만능이라는 오해가 퍼져 있으나 수학적 조건 따져가며 적용해야
Borel-measure 조건을 충족시키지 못하는 계산에서는 '학습 실패' 사건이 벌어지기도
오차 많은 시계열 데이터에서 빈번하게 발생, 데이터 전처리 고민 필수
우리 SIAI 학생 중 한 명의 미국 대학원 추천서를 쓰면서, SIAI에서 가르친 내용, 방향, 수준, 응용 방식을 잘 보여주면서, 동시에 그 학생의 역량을 쉽게 이해할 수 있는 예제가 뭐가 있을까는 고민을 해 봤다.
Deep learning 수업에서 RNN을 가르치던 중에 Neural Network가 적용될 수 있는 한계를 수학적으로 짚어주고, 그 수학 개념 뒤에 숨어있는 현실적인 제한을 풀어내 준 적이 있었는데, 그걸로 한 동안 학생들끼리 어떤 데이터를 어떻게 수정해야하는지에 대한 고민을 나눴던 기억이 있다.
코딩 라이브러리 하나 불러와서 이것저것 넣어보다가 결과값이 자기 입맛에 맞게 나오면 쓰고 있는 대부분의 2류 교육과는 본질적으로 다른 교육을 했다는 것을 보여주고 싶기도 했고, 수학적인 개념을 이해해서 현실 데이터와 모델에 응용할 수 있는 역량을 갖췄다는 것을 그 학생의 추천 포인트로 삼고 싶기도 했기 때문에, 여러 고민 중에 이 주제를 골랐다.
Neural Network 계산의 본질과 한계
비전문가들 사이에서는 마치 Neural Network가 기존 모든 계산을 다 압도하는 최고의 계산법이라는 착각이 널리 퍼져있지만, 실제로 Neural Network 계산 자체는 그래프 모델에서 Factor analysis를 반복적으로 하는 것에 불과하다. 데이터의 구조와 모델의 목적이 잘 맞는 경우에는 모든 경우의 수를 다 구현해낼 수 있는 계산이 될 수 있지만, 데이터가 수학적인 요건을 못 만족시킬 때 모델의 목적을 맞추려고 계산식을 변형하거나, 최악의 경우에는 포기해야하는 사태가 발생할 수도 있다.
시계열 데이터가 대표적인 예시인데, 그래프 모델의 비선형성을 활용하고 싶어도 Outlier가 지나치게 많을 경우에는 모델 값이 수렴하지 않는다. 수식으로 간단하게 쓰면, y=f(x)라는 함수에서 x와 y가 모두 문제가 없더라도 f(·) 함수가 정의되지 못하는 상황인데, 대학 학부 수준의 수학으로는 Borel-measure가 성립하지 않는 상태, 고교 수학 수준으로 표현하면 '발산'하는 사건이 발생하는 경우라고 표현할 수 있다. 좀 더 일반인에게 친근한 용어로 쓰면, '인공지능이 학습하지 못하는 계산'이라고 할 수 있겠다.
이 때는 Outlier를 제거하는 데이터 전처리 작업에 대한 고민을 하거나, 데이터(x) 형태를 변형하는 방법, f(·) 함수를 변형하는 방법 등의 대안들이 존재한다. 물론 각각의 방법을 주먹구구식으로 쓰는 것이 아니라, 데이터의 특성과 계산 목적에 맞게 변형해야하는데, 이 부분이 고급 수학을 응용할 수 있는 직관적인 역량이 중요한 순간이다.
Borel-measure라는 표현 속에 숨겨진 데이터의 특성과 계산의 목적
뜬금없는 수학 개념인 Borel-measure가 매우 어려운 개념처럼 들릴 수도 있지만, 사실 우리가 고교 시절에 봤던 합집합, 차집합 등의 개념이 적용되는 집합이라는 간단한 용어로 정의된다. 매우 쉬운 예제를 들면, 자연수는 덧셈, 곱셈만 자연수 결과값이 나오고, 뺄셈과 나눗셈에서는 자연수가 아닌 결과값이 나올 수 있다. 더 큰 숫자로 뺄셈을 하면 음수가 나오고, 약수로 나눗셈을 하지 않으면 분수 같은 유리수가 나온다.
고교 수준, 혹은 그 이하 수학으로 충분히 이해할 수 있는 개념이지만, 위의 Neural Network 활용 가능성을 점검하는 논의까지도 확장될 수 있다. 덧셈, 뺄셈 등의 단순한 예시를 들었던 함수 f(·)가 Neural Network에서는 Activation Function으로 불리는데, 이 때 그 함수가 Borel-measure의 범위 밖에 있는 값을 줄 경우에는 뺄셈과 나눗셈이 자연수를 못 만들어내는 것과 마찬가지로 Neural Network가 계산값을 제공해주지 못하기 때문이다.
가장 자주 이런 현상이 나타나는 데이터는 주식 시장의 수익률 데이터처럼 굉장히 많은 랜덤 요소를 담고 있는 경우가 있고, 그 외에도 단순한 논리에 따라 결과값이 떨어지지 않는 대부분의 데이터가 수준만 다를 뿐, Borel-measure 요건을 충족시키지 못하는 데이터 구간을 갖고 있다.
공학적 용어로 '학습에 실패'한 상황을 피하기 위해서 데이터의 형태를 변경하거나, 함수 f(·)의 형태를 변경하는 절차를 거칠 수도 있고, Neural Network 계산법이 적절하지 않은 데이터인만큼 다른 계산법으로 접근 방향을 바꿔야 할 수도 있다.
Neural Network도 여러 계산법 중 하나, 언제나 핵심은 데이터, 모델, 그리고 계산 목적
전세계적으로 많은 기업들이 단순한 Neural Network 계산 코드 한 줄만 넣으면 AI 기술 개발이 되는 줄 착각하는 임원단과 라이브러리 갖다 쓰기 바빴던 초급 개발자들에게 현혹되어 AI 전문가에 대한 관점이 잘못된 채로 몇 년을 보냈다. 그러다 전문 인력들이 문제를 지적하면서 시장이 개선되는 중인데, 대부분의 공학 전공들이 수학 교육을 불충분하게 한 상태이다보니 위와 같은 직관적인 개념 이해도 부실해진 경우들을 자주 본다.
굳이 해석개론 수준의 Borel-measure 개념 없이도 데이터 문제로 계산이 불가능한 경우들이 있다는 것이 널리 알려졌다면 많은 기업들이 엉뚱한 인건비를 버리지 않아도 됐을지 모르지만, 안타깝게도 수학 개념을 이해하는 분들이 많지 않은 나라와 산업에서는 기술 개발에 실패하면서 사업주들이 각종 비용을 짊어져야 했다.
SIAI에서 그렇게 훈련을 받은 학생이 미국 유학 중에 또 어떤 도전을 겪을지 알 수 없지만, 최소한 위외 같은 시행착오는 피할 수 있는 훈련이 된 만큼, 미국 기업들이 원하는 경험치를 학교에서 쌓아서 졸업할 수 있게 되기를 기대한다.
Picture
Member for
9 months 2 weeks
Real name
Keith Lee
Bio
Keith Lee is a Professor of AI and Data Science at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI), where he leads research and teaching on AI-driven finance and data science. He is also a Senior Research Fellow with the GIAI Council, advising on the institute’s global research and financial strategy, including initiatives in Asia and the Middle East.