
Member for
5 monthsProfessor of AI/Data Science @ SIAI
Input
Generative models are simply repeatedly updated model. Unlike discriminative models that we have learned from all previous lectures, such as linear/non-linear regressions, SVM, tree models, and Neural Networks, Generative models are closely related to Bayesian type updates. RBM (Restricted Boltzmann Machine) is one of the example models that we learned in this class. RNN, depending on the weight assignment for memory, can qualify generativeness.
To further help you to understand the difference, let's think about K-means. Once you have a fixed group, there is not much we can do, unless we run the same code to find another matching group. Then, what if there is a point that is nearly arbitrary to claim either group A or B. We may assign 50:50 probability, but K-means does not support such vagueness. Gaussian Mixture Model (GMM), however, assumes that there are N number of gaussian processes in the data, so a point at an overlapping area between group A and B can earn some probability (in terms of Z-stat) for its group assignment. The grouping is updated recursively, which qualifies generativeness.

With some Bayesian type updating between Prior and Posterior, we term them as EM algorithm.
- E-step: Compute the posterior probability that each Gaussian generates each datapoint
- M-step: Assuming that the data really was generated this way, change the parameters of each Gaussian to maximize the probability that it would generate the data it is currently responsible for
Like we did with Gibbs sampling (and RBM), the model eventually converges as long as it fits all mathematical properties.

The same process can be applied to any data that we don't know the hidden forms of underlying distribution and target distribution. For example, Latent Dirichlet Allocation (LDA), one of the most fundamental and popular natural language model, assumes that words in paragraphes have hidden variables, which it calls 'topic'. Simply put, each paragrah should have a few topics, but until one reads the paragraph carefully, it is not easy to capture the topics. LDA, with a vague assumption of the hidden variables, without any deterministic density information of words, finds hidden topics. The topics help us to find what are the contents of the paragraph, the section, and the book.
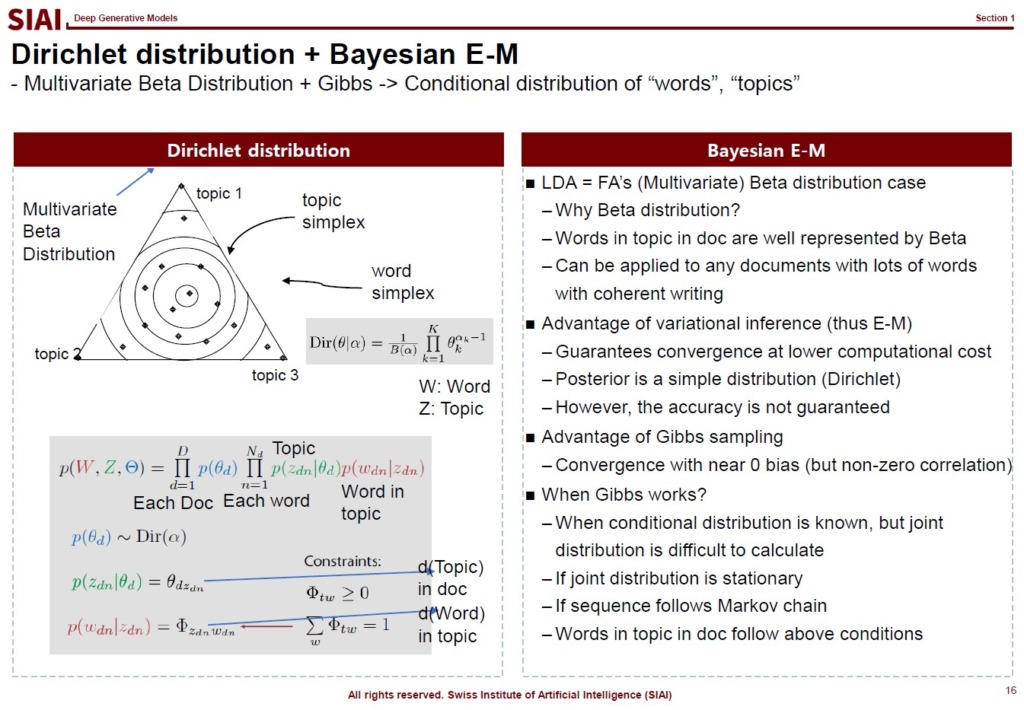
From autoencoder to GMM and LDA, due to interdependency between the input and output layers of network, all neural network models need some level of generative construction process, unless the universally fitted form of network is known.
It may sound too cumbersome, especially for researchers from analytic solutions, but the data that we have is highly irregular that we often have to rely on computational solutions.
Member for
5 monthsProfessor of AI/Data Science @ SIAI




Comment